Migration from v1.0 to v2.0
What you should do to migrate your TAP service from v1.0 to v2.0.
V2.0, in brief...
In addition of the correction of several bugs in the 3 libraries, some parts of the TAP library have changed. Consequently, if you developped your TAP service with the version 1.x, it should not be totally compatible any more with the new version. The following section will explain in more detail what you should modify in some files of your implementation to upgrade more easily your service. But basically here are the main modifications that you should know between v1.x and v2.0:
Metadata
Upload
- The Upload feature has totally moved into the UWS library.
- Deletion of TAPFileManager.
Since UWSFileManager is now able to support uploads, there was no need to keep TAPFileManager which were designed only to support uploads.
Output
- VOTable supported thanks
STIL
instead of SAVOT.
The idea is to be able to deal with VOTable, FITS and eventually other input/output formats with only one library. - Simplification of the default implementations of OutputFormat.
These new implementations only deal with the formatting itself rather than also dealing with the result reading. An iterator makes this reading abstract for its users.
Database interaction
Simplification of the interface DBConnection.
The interface has been modified in order to keep all the technical aspects about how to interact with the DB
inside its implementation. It is then no longer possible to deal with transactions outside of this class ; they are managed
inside the class which should ensure more stability. Consequently, there are now functions like
addUploadedTable(TAPTable, TableIterator)
and getTAPSchema() which lets perform exactly what is
needed by the library.
TAP factory
- TAPFactory is no longer an interface but an abstract class which implements some UWS related functions.
-
Management of database connections
2 new functions which lets get and free connections. - AbstractTAPFactory leaves UNimplemented ONLY DB connection's related functions and destroy() (which lets free any open resources while shutting down the service).
Service description
5 new functions added:
How to migrate? Instructions to follow to go to v2.0
This section lists the main modifications to apply to your code in order to use v2.0 of the library instead of v1.x. Since this library lets customize several parts of a TAP service, some modifications you need to do may not be listed here. For those customized points, I advise you to look at the documentation, javadoc and/or GitHub commits. Here, only the most important modifications are listed ; they have been tested on the DemoASOV package delivered with the version 1.0 of the library.
1. In all classes
...and more particularly of the following classes:
One of the big changes between the version 1.0 and 2.x, is the removal of all generic types (e.g.
TAP<ResultSet>). This was indeed an awkward solution which had more constraints than flexibility. Without them, the syntax should be simpler.
In v1.0
public class DemoTAP_TAPFactory extends AbstractTAPFactory<ResultSet> {
protected DemoTAP_TAPFactory(ServiceConnection<ResultSet> service) throws NullPointerException{
super(service);
}
public ADQLTranslator createADQLTranslator() throws TAPException{
return new PgSphereTranslator();
}
public DBConnection<ResultSet> createDBConnection(String jobId) throws TAPException{
return new DemoTAP_DBConnection(jobId);
}
}
In v2.0
public class DemoTAP_TAPFactory extends AbstractTAPFactory {
protected DemoTAP_TAPFactory(ServiceConnection service) throws NullPointerException{
super(service);
}
public ADQLTranslator createADQLTranslator() throws TAPException{
return new PgSphereTranslator();
}
public DBConnection createDBConnection(String jobId) throws TAPException{
return new DemoTAP_DBConnection(jobId);
}
}
2. In your extension of DBConnection (if any)
Except getID() and executeQuery(...), all the other functions of DBConnection have been deleted. Besides, executeQuery(...) has one parameter less. Then, you must rewrite an important part of your implementation (but former functions can still remain and be used for the new ones).
If you are using a JDBC driver to access your database, there is no need to implement or extend a class of the library: the concrete class JDBCConnection is already implementing all functions of the interface.
It has been tested with a PostgreSQL and SQLite database. Types and SQL syntaxes of PostgreSQL, SQLite, MySQL, Oracle and JavaDB should be also supported.
The functions of the interface DBConnection have undergone a lot of modifications.
The idea behind them is to move the database logic into DBConnection,
so that the other classes of the library do not have to deal with transactions, database types, etc...
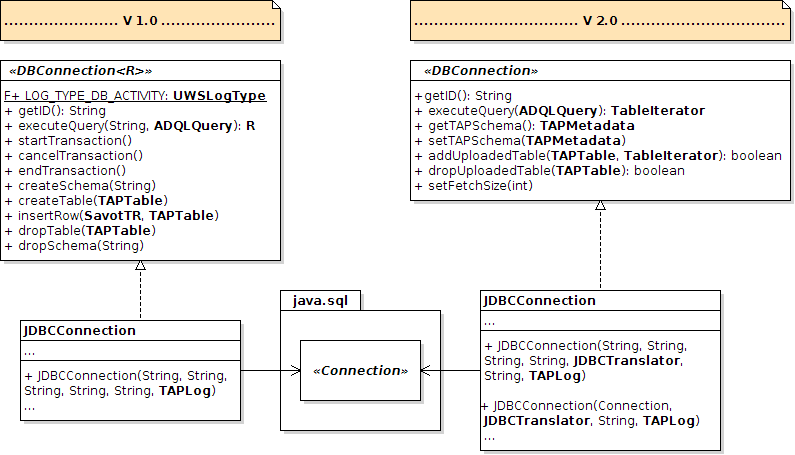
As you can see on the UML diagram. this last version of the library still provides the default implementation
JDBCConnection. And of course, it has been modified so
that being able to deal as nicely as possible with transactions and types. It is even able to detect whether
transactions are supported by the database and whether the database has the notion of schemas (for instance,
SQLite does not have this notion). Management of types and their conversion into TAP types is better managed than in
v1.0 ; types of the main RDBMS should be totally detected and converted.
3. In TAPFactory
AbstractTAPFactory,
because it already implements all functions for which the library already provides a default implementation. In this new version,
only functions related to the management of the database connections have to be implemented.
createQueryChecker(TAPSchema)
This function is fully implemented by default and should not be any more overriden, except if you want to return your own
extension of QueryChecker.
The default one will return a
DBChecker,
initialized with all tables listed in the TAP metadata.
createADQLTranslator()
This function does not exist any more. The translator must be set at the creation of a
DBConnection.
createDBConnection() to getConnection(String)
JDBCConnection
The constructor of v1.0 has been indeed slightly modified: the 1-st parameter in v1.0 is now at the 6-th position, and
now a JDBCTranslator
is requested. As explained the logic has been moved as most as possible inside the
DBConnection, and so the translation too. Besides, you also have a new constructor, which just wraps
a given JDBC connection.
If you are using a JDBCConnection, the only way to free resources of a DB connection is to get the embedded connection (using getInnerConnection()) and to close it (using Connection.close()).
destroy()
If you have allocated resources (e.g. connection pool) in the factory, they must be released in this function. This function is called by the library only once: when the web service is shutting down.
More explanations about the configuration of the factory can be found in this Getting Started.
In v1.0
public class DemoTAP_TAPFactory extends AbstractTAPFactory<ResultSet> {
protected DemoTAP_TAPFactory(ServiceConnection<ResultSet> service) throws NullPointerException{
super(service);
}
public ADQLTranslator createADQLTranslator() throws TAPException{
return new PgSphereTranslator();
}
public DBConnection<ResultSet> createDBConnection() throws TAPException{
return new DemoTAP_DBConnection();
}
}
In v2.0
public class DemoTAP_TAPFactory extends AbstractTAPFactory {
protected DemoTAP_TAPFactory(ServiceConnection service) throws NullPointerException{
super(service);
}
public DBConnection getConnection(final String jobId) throws TAPException{
return new JDBCConnection("org.postgresql.Driver", "jdbc:postgresql:" + DemoASOV.DB_NAME, DemoASOV.DB_OWNER, DemoASOV.DB_PWD, new PgSphereTranslator(), jobId, service.getLogger());
}
public void freeConnection(DBConnection conn){
try{
((JDBCConnection)conn).getInnerConnection().close();
}catch(SQLException se){
service.getLogger().error("Can not close the connection " + conn.getID(), se);
}
}
public void destroy(){
// nothing special to do here!
}
}
4. Service description
log(LogType, String)
Logging is now done using an instance of TAPLog that must be also created and provided in this service description. (see below for the corresponding instructions)
deleteResults(ADQLExecutor)
The streams and files related to query results are now completely managed by a UWSFileManager.
getUploadDirectory()
As well storage of uploaded files is complemented managed by a UWSFileManager.
TAPFileManager to UWSFileManager (if you have any)
TAPFileManager existed just to extend UWS in order to add the Upload capability. But since this feature has moved in
the UWS Library, all related functions have moved inside
UWSFileManager.
LocalTAPFileManager to LocalUWSFileManager (if you have any)
OutputFormat
Here are the corresponding objects in the new version:
| In v1.0 | In v2.0 |
|---|---|
| VOTableFormat<R> & ResultSet2VotableFormatter | VOTableFormat |
| SVFormat<R> & ResultSet2SVFormatter | SVFormat |
| JsonFormat<R> & ResultSet2JsonFormatter | JSONFormat |
| TextFormat<R> & ResultSet2TextFormatter | TextFormat |
| FitsFormat | |
| HTMLFormat |
In v1.0
outputFormats = OutputFormat<ResultSet>[2]; outputFormats[0] = new ResultSet2VotableFormatter(this); outputFormats[1] = new ResultSet2SVFormatter(this, ",", true);
In v2.0
outputFormats = new OutputFormat[2]; outputFormats[0] = new VOTableFormat(this); outputFormats[1] = new SVFormat(this, ",", true);
For more flexibility the structure storing the allowed output formats is not any more forced to be an array. Now, just an iterator is asked ; an iterator could indeed let iterate over a Collection but also over a simple array.
In v1.0
...
private final OutputFormat[] formats;
...
public MyServiceConnection() throws UWSException{
...
formats = new OutputFormat[2];
formats[0] = new DemoTAP_VOTableFormatter(this);
formats[1] = new DemoTAP_CSVFormatter(",");
}
...
public OutputFormat[] getOutputFormats(){
return formats;
}
...
In v2.0
...
private final ArrayList<OutputFormat> formats;
...
public MyServiceConnection() throws UWSException{
...
formats = new ArrayList<OutputFormat>(2);
formats.add(new VOTableFormat(this));
formats.add(new SVFormat(this, ",", true));
}
...
public Iterator<OutputFormat> getOutputFormats(){
return formats.iterator();
}
...
In v1.0
...
public long[] getExecutionDuration(){
return new long[]{3600,7200};
}
...
In v2.0
...
public int[] getExecutionDuration(){
return new int[]{3600,7200};
}
...
getFileManager()
You must first create an instance of a UWSFileManager in the constructor of your ServiceConnection. This instance must be stored as class attribute. The function getFileManager() will just return it. This object will be very useful for the library in order to store results, errors, logs and backups.
An implementation of UWSFileManager already exists: LocalUWSFileManager. It stores all TAP service's files in a local root directory specified in parameter of the constructor.
...
private final UWSFileManager fileManager;
public MyServiceConnection() throws UWSException{
// Create a TAP files manager:
fileManager = new LocalUWSFileManager(new File("MyTAPFiles"));
...
}
public UWSFileManager getFileManager(){
return fileManager;
}
...
getLogger()
As said previously log messages are not any more logged using a function inside ServiceConnection, but with an instance of TAPLog. As for the file manager, this instance must be created in the constructor and stored as class attribute in order to be get using the new function getLogger().
...
private final TAPLog logger;
public MyServiceConnection() throws UWSException{
...
logger = new TAPLog(fileManager);
}
...
public TAPLog getLogger(){
return logger;
}
...
This function must change what isAvailable() and
getAvailability() return.
In v2.0, the first function is used by the library to forbid access to the /sync and /async resources.
Thus, using
setAvailable(boolean, String)
would then let you control access of the service by clients at any moment.
It is strongly recommended to set the "available" flag to false. Once the HTTP servlet will be initialized,
the library will call the function
setAvailable(boolean, String) in order
to enable the executive resources /sync and /async.
In v1.0
...
public boolean isAvailable(){
return true;
}
public String getAvailability(){
return null;
}
...
In v2.0
...
private boolean available = false;
private String availability = "TAP service not yet initialized!";
...
public boolean isAvailable(){
return available;
}
public String getAvailability(){
return availability;
}
public void setAvailable(boolean isAvailable, String message){
available = isAvailable;
availability = message;
}
...
getGeometries()
This function must return the list of all ADQL geometrical functions that are allowed ; if any other is used in an ADQL query, this
one will be rejected. Thus, if the function returns an empty list, no geometrical function will be allowed. If NULL is
returned, all geometrical functions are allowed.
...
private final ArrayList<String> allowedGeometries;
public MyServiceConnection() throws UWSException{
...
allowedGeometries = new ArrayList<String>(5);
allowedGeometries.add("POINT");
allowedGeometries.add("circle");
allowedGeometries.add("Box");
allowedGeometries.add("CONTAINS");
allowedGeometries.add("intersects");
}
...
public Collection<String> getGeometries(){
return allowedGeometries;
}
...
getUDFs()
As getGeometries(), this function must also return
a list of allowed functions. However, instead of a waiting a String (corresponding to the function name), here a function definition
- FunctionDef - is expected. If an empty list
is returned by this function, an error will be thrown each time an unknown function is encountered in an ADQL query. But if
NULL is returned, unknown functions will be allowed.
...
private final ArrayList<FunctionDef> allowedUdfs;
public MyServiceConnection() throws UWSException, TAPException{
...
allowedUdfs = new ArrayList<FunctionDef>(4);
try{
allowedUdfs.add(FunctionDef.parse("trim(txt String) -> String"));
allowedUdfs.add(FunctionDef.parse("lower(txt varchar) -> VARCHAR"));
allowedUdfs.add(FunctionDef.parse("upper(txt varchar) -> VARCHAR"));
allowedUdfs.add(FunctionDef.parse("random() -> double"));
}catch(ParseException pe){
throw new TAPException("Can not initialize the TAP service! There is a wrong UDF definition: " + pe.getMessage(), pe);
}
}
public Collection<FunctionDef> getUDFs(){
return allowedUdfs;
}
...
This function lets limiting the number of asynchronous queries that can run in parallel. If more asynchronous queries than the returned value are submitted, they will be queued. If a value ≤ 0 is returned, the number of asynchronous queries is unlimited.
ServiceConnection.getNbMaxAsyncJobs()
used with a DB connection pool let save server resources by controlling the number of running queries. Indeed, if a
connection pool is implemented in the TAPFactory, you can control
the number of running (async + sync) queries. Then, with
ServiceConnection.getNbMaxAsyncJobs()
you set the maximum number of asynchronous queries, and so indirectly the number of synchronous queries (i.e. nbMaxConnection -
nbMaxAsyncJob).
This function lets limiting the size of all files uploaded in once. It is not the same limit as the one returned by
getUploadLimit() when the unit is rows. Indeed
this latter counts only the whole size of data to upload (i.e. no metadata or file syntax characters...just the columns values) while
getMaxUploadSize()
considers the size of the uploaded set of files. So, be sure that this value is always bigger than the upload limit on rows.
In case the UPLOAD feature is enabled, a positive and not null value must always be returned by this function. Otherwise an
exception may be thrown. The only possible maximum value is Integer.MAX_VALUE (i.e. ~2MB).
If the UPLOAD is disabled, this function is never taken into account.
getFetchSize()
The value returned by this function represents the iterative number of rows that must be fetch from the database when a query results is retrieved. If positive and not null, query results will be fetched by bunch of rows whose the size (i.e. number of rows) will be the set value. Otherwise, the JDBC driver will wait that all rows are collected before sending the ResultSet to the TAP service.
Setting this value correctly may allow better performances. Indeed, what is taking most of the time when executing a query is the retrieval of data...not the query resolution or the selection of rows, especialy if index(es) are used. Thus, it will first allow to cancel quite immediately a job because otherwise the corresponding DB thread will be stop only when all rows will be ready...which is then too late to cancel the query. Secondly, setting this value will allow a streaming output when used for synchronous jobs: depending of the chosen result format, the rows will come by bunches of rows rather than in once.
This function must then return an array of maximum 2 values. The first one which will apply for asynchronous jobs, and the second for synchronous jobs. A negative or null value will be interpreted as "wait for all rows". Generally, it is a good idea to set the value for synchronous jobs only (see the below example).
...
public int[] getFetchSize(){
return new int[]{-1, 10000}; // Synchronous: 10 000 rows per 10 000 rows ; Asynchronous: wait for the whole result
}
...
5. User identification
Rather than returning just an identifier, this function must now return an object implementing the interface JobOwner. A default implementation lets create a such object with just an ID and with eventually an pseudo/name: DefaultJobOwner.
restoreUser(String, String, Map)
This function is used only when a job must be created from a backup. Consequently, if it is not implemented, no user can be restored at a service start up.
In v1.0
...
private final UserIdentifier identifier;
public MyServiceConnection() throws UWSException, TAPException{
...
// Create a way to identify users (by IP address):
identifier = new UserIdentifier(){
public String extractUserId(UWSUrl urlInterpreter, HttpServletRequest request) throws UWSException{
return request.getRemoteAddr();
}
};
}
public UserIdentifier getUserIdentifier(){
return identifier;
}
...
In v2.0
...
private final UserIdentifier identifier;
public MyServiceConnection() throws UWSException, TAPException{
// Create a way to identify users (by IP address):
identifier = new UserIdentifier(){
public JobOwner extractUserId(UWSUrl urlInterpreter, HttpServletRequest request) throws UWSException{
return new DefaultJobOwner(request.getRemoteAddr());
}
public JobOwner restoreUser(String id, String pseudo, Map<String,Object> otherData) throws UWSException{
return new DefaultJobOwner(id, pseudo);
}
};
}
public UserIdentifier getUserIdentifier(){
return identifier;
}
...
6. Definition of table and column metadata
In v1.0, to declare tables and columns to publish, you had only the manual solution: create instances of
TAPTable and
TAPColumn.
Now, you can also import these metadata directly from the database schema TAP_SCHEMA thanks to the function
DBConnection.getTAPSchema().
All standard tables and columns are then automatically converted into
TAPTables and
TAPColumns. This new solution is strongly recommended
because it ensures the consistency between the database and the internal representation in the service ; in other words,
between what is returned when the schema TAP_SCHEMA is interrogated with an ADQL query and the resource
/tables.
public MyServiceConnection() throws TAPException, DBException, UWSException{
...
DBConnection dbConn = factory.getConnection("MetaConn");
metadata = dbConn.getTAPSchema();
getFactory().freeConnection(dbConn);
...
}
Another quick solution is also proposed in this new version of the library: parse an XML document following the XML schema
described by the IVOA in VODataService. Actually this document
looks exactly like what will be returned by the resource /tables. Its root node is tableset and
schema, tables, columns and foreign keys are listed and described there.
To convert a such document into a TAPMetadata object, you must use the parse named TableSetParser. Below is an example of it could be used:
...
private final TAPMetadata meta;
public MyServiceConnection() throws TAPException, DBException, UWSException{
...
// Get the metadata from the given XML document:
meta = (new TableSetParser()).parse(xmlFile);
// Update the TAP_SCHEMA schema in database:
DBConnection dbConn = factory.getConnection("MetaConn");
metadata = dbConn.setTAPSchema(meta);
getFactory().freeConnection(dbConn);
...
}
public TAPMetadata getTAPMetadata(){
return meta;
}
...
TAP_SCHEMA?
When retrieving metadata from an external source (like a file or with a manual solution), there is a big risk that
the database does not have the schema TAP_SCHEMA or that the data inside it matches the retrieved one.
So calling setTAPSchema(TAPMetadata)
will update TAP_SCHEMA in the database so that matching exactly what the XML file contains. The schema
may obviously be created if needed.
Consequently, if you are not retrieving metadata from the database schema TAP_SCHEMA, you are strongly
encouraged to call setTAPSchema(TAPMetadata)
!
Of course, the DB user specified for each DB connection must be able to modify the structure of at least the schema
TAP_SCHEMA. Write permission is needed only for this schema and TAP_UPLOAD. Otherwise,
for all other operations (i.e. only executing an ADQL query...so a SELECT), only a read permission is required.
However, if you still want to use the manual solution, you have to modify your existing metadata creation in order to adapt it to v2.0. The following points have been modified:
- The table type is now an enum class -
TableType- instead of a String value. - Column types are better supported in v2.0. Thus, there is now one class to represent a column type,
whereas before this information was composed of 2 separated values (a String and an integer):
DBType.
Considering these two major modifications, the constructors and some functions of these two classes have slightly changed ;
generally, the type and the position of a parameter in the parameters list have changed. Take a look to the following example
to see such modifications applied to the functions addTable(String, TableType, String, String) and
TAPTable.addColumn(String, DBType, String, String, String, String).
In v1.0
TAPTable t = tapSchema.addTable("schemas");
t.addColumn("schema_name", "schema name, possibly qualified", null, null, null, "VARCHAR", 32, true, true, true);
t.addColumn("description", "brief description of schema", null, null, null, "VARCHAR", 255, false, false, true);
t.addColumn("utype", "UTYPE if schema corresponds to a data model", null, null, null, "VARCHAR", 255, false, false, true);
In v2.0
TAPTable t = tapSchema.addTable("schemas");
t.addColumn("schema_name", new DBType(DBDatatype.VARCHAR, 32), "schema name, possibly qualified", null, null, null, true, true, true);
t.addColumn("description", new DBType(DBDatatype.VARCHAR, 255), "brief description of schema", null, null, null, false, false, true);
t.addColumn("utype", new DBType(DBDatatype.VARCHAR, 255), "UTYPE if schema corresponds to a data model", null, null, null, false, false, true);
TAP_SCHEMA
As already said just above, when using the manual method, it is strongly recommended to update the database
with the created metadata, so that having the same output with an ADQL query on the schema TAP_SCHEMA and
with an HTTP-GET request on the resource /tables. To do that, you just have to call the function
DBConnection.setTAPSchema(TAPMetadata).
...
public MyServiceConnection() throws UWSException, TAPException{
...
// Update the database schema TAP_SCHEMA:
try{
DBConnection dbConn = tapFactory.getConnection("MetaConn");
dbConn.setTAPSchema(metadata);
tapFactory.freeConnection(dbConn);
}catch(DBException de){
throw new TAPException("Can not update the database with the given metadata!", de);
}
...
}
...
7. Set the service as available
If you have set the "available" flag to false as suggested above, you have now to enable your TAP service at
the end of the init(...) function of your servlet. You do that with the function
setAvailable(booleam, String).
public class MyTAPServlet extends HttpServlet {
private TAP tap = null;
public void init(final ServletConfig config) throws ServletException{
super.init();
try{
// 1. Create a TAP instance with the written ServiceConnection:
tap = new TAP(new MyServiceConnection());
// Set the service available:
tap.getServiceConnection().setAvailable(true, "Demo's TAP service available!");
}catch(Exception e){
throw new ServletException(e);
}
}
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException{
// 2. Forward all requests to the TAP instance:
tap.executeRequest(request, response);
}
Still have an error?
At this stage, the old demo code (called DemoASOV), taken as example for all these migration instructions, does not have error any more and is fully functional. However, your implementation may still have some errors. In this case, you could merely follow the errors and try to fix them by yourself ; most of these errors should be simple to fix. If not, you can take a look to this Getting Started for comparison with what you have and you have implemented the factory and service description. Besides, the Javadoc of the library is complete and may be very helpful for you. And obviously, the documentation on this website may asnwer your questions.
If you still have problems that you figure out, you can send me an email. I will try to answer you as quick as possible.