Getting started
How to build in few steps a basic TAP service.
Introduction
Creating a TAP service implies creating a Web service able to interact with of course a Web client (e.g. Web browser, command shell, standalone application, Web application) but also with a database, a file system (local or remote), and a lot of threads. The TAP Library aims to deal with the whole protocol defined by the IVOA. However, because so many aspects have to be taken into account, some information must be provided to the library. What is explained in this Getting Started is how to provide the minimal configuration to the library in order to set up a running and functionnal TAP service. Only 3 Java classes must be written. Hence the division of this Getting Started in 3 main parts:
- Set database access. Tell the library how to discover, query but also add schemas to your database.
- Service description. Tell where service's files must be stored, what should be the limits of the service, ...
- Write the servlet. Create the TAP service with the previously written configuration and link it to your Web Server Application.
So now, let's start with the most important: the database access!
To start this Getting Started, you can use the following archive to deploy in your web application server. It already contains the basic directories of a web application, the library JAR file and empty files that you will fill little by little while following this Getting Started.
I. Set database access
The first and the most important thing to do is obviously configuring the way the TAP service will access the database. A database is generally a relationnal SQL database managed by a DBMS. The most famous ones are Oracle, PostgreSQL, MySQL and SQLite. In this Getting Started, only the access to a such kind of database will be explained ; PostgreSQL will be particularly taken as example. However the library does not constrain any particular DBMS or database type, so you are free to use your own method. In this case, the following explanations should be used as an example of how database connections are used by the library.
1. JDBC driver
In order to establish a connection to a SQL database in Java, the interface JDBC must be used. This interface is implemented differently in function of the type of database. That's why the JDBC driver of your DBMS must be provided in the classpath of your Web Application Server. To do so, you have too choices:
- in the classpath of the service:
WEB-INF/lib - in the classpath of your Web Application Server: e.g. for Tomcat,
{TomcatHome}/lib
2. ADQL translation
ADQL is a language really close to SQL. In addition of slight syntax differences, the only real difference is the ADQL geometrical functions which have no equivalent in native SQL. For those special functions, an extension must be installed in the DBMS ; for instance PgSphere or Q3C in the case of PostgreSQL.
In any case, even if geometrical functions of ADQL are not used in your TAP service, you must say to the library
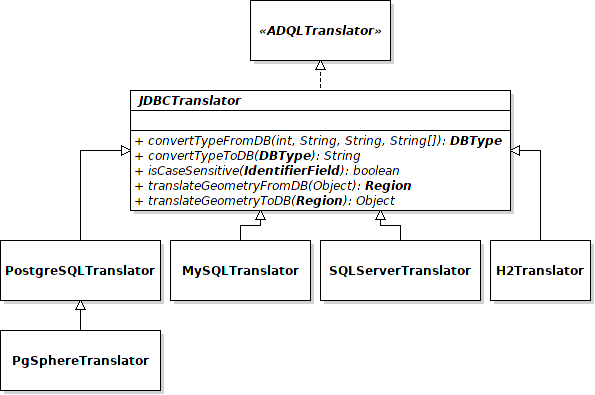
how to translate ADQL queries into SQL. For that, an implementation of JDBCTranslator
must be provided while building a connection. For the moment 5 concrete extensions of this class exist:
PostgreSQLTranslator,
PgSphereTranslator (PostgreSQL +
implementation of geometrical functions),
MySQLTranslator
SQLServerTranslator and
H2Translator.
These five classes are the only concrete implementations provided by the library for the moment. You are however free to create your own(s) in function of your needs.
In the next steps, we will suppose that the translator is:
PostgreSQLTranslator. Particularly because it
does not require the installation of any DBMS extension. So, feel free to change it in the following code to match your DBMS
and its configuration.
3. 3 approaches using JDBC
Here, three different methods to configure an access to a database will be introduced. They will be presented from the simplest to a most elaborated method.
In all of them, only one class will be created: an implementation of TAPFactory.
As this name suggests, this interface is a factory used by the library to build important classes. In the facts,
implementing this interface would mean writing 26 functions. That is of course out of the question! So instead, we
will extend an abstract implementation: AbstractTAPFactory.
Thus we reduce considerably the number of functions to implement from 26 to only the 3 following ones:
getConnection(String connID): to create aDBConnectionwith the given name/ID.freeConnection(DBConnection): to "close" the given database connection.destroy(): to destroy any resources managed by this factory.
java.sql.Connection directly
but with a wrapping of it called tap.db.DBConnection.
The interest is particularly to limit and simplify the number of operations to perform on the database. Thus,
it is not possible to execute any SQL queries: only ADQL queries are accepted in parameter in order to be
translated into SQL interrogation queries. As well, modifications (e.g. update, drop, delete) are not directly possible
and are much more limited.
Now, let's start writing this class. Below are the first lines to write in the file MyTAPFactory.java ; if you are using
the given Web Application skeleton put this new file in WEB-INF/sources:
import tap.AbstractTAPFactory;
import tap.ServiceConnection;
import tap.TAPException;
import tap.db.DBConnection;
import tap.db.JDBCConnection;
import adql.translator.PostgreSQLTranslator;
import uws.service.log.UWSLog.LogLevel;
import java.sql.Connection;
import java.sql.SQLException;
public class MyTAPFactory extends AbstractTAPFactory {
}
Since a constructor is defined in this abstract class we must create one which will use the one of the abstract class.
public MyTAPFactory(final ServiceConnection serviceConn){
super(serviceConn);
}
Now, all we have to do is to implement the 3 functions listed previously. But, of course, in function of how database connections will be created and managed, the implementation of these methods will change. So now, we are going to see the three methods of database access mentionned at the beginning. Thus, you will be able to choose which one your want to use, but you will also able to understand enough how to deal with DB connections with the TAP Library.
Method 1: One-shot connection
Using DriverManager.getConnection(...)
is the simplest and most famous way to create a DB connection. That's why we start by this method!
Basically the way to proceed is always the same:
- Load the JDBC driver (or ensure it is loaded),
- Get a connection by providing the driver name, the database JDBC URL, the DB user to use and its password.
All this is already done by JDBCConnection when using its constructor:
JDBCConnection(String driver, String dbUrl, String user, String pwd, JDBCTranslator translator, String connID, TAPLogger logger).
Particularly, this constructor is testing whether the JDBC driver is loaded, and if not, load it using
DriverManager. So, the creation of a connection
is really simple and reduced to the following line:
public DBConnection getConnection(final String connID) throws TAPException{
return new JDBCConnection(JDBC_DRIVER, DB_URL, DB_USER, USER_PWD, new PostgreSQLTranslator(), connID, this.service.getLogger());
}
As said previously this function will be used by the library when an access to the database is required. The library gets/creates a connection,
uses it and its job is finished it must close the connection. This is then done by calling the function
freeConnection(DBConnection). In this method, all
we have to do, is to merely close the connection, but since it is embedded in the DBConnection
we first get the java.sql.Connection object and then call
its "close" function:
public void freeConnection(final DBConnection dbConn){
try{
((JDBCConnection)dbConn).getInnerConnection().close();
}catch(SQLException se){
service.getLogger().logTAP(LogLevel.WARNING, dbConn, "CLOSE_CONNECTION", "Can not close the connection!", se);
}
}
Since connections are closed immediately after its use, nothing has to be done in the destroy()
function. So this function is left with an empty body.
public void destroy(){
}
The implementation of the factory is then complete! The library is now able to access the database. But as said at the beginning, this is the simplest method and 2 other are following. So what is the interest of using one of the following methods if they are more complicated while the first one is simple and works? The reason is just about optimization. Let's see what is it about with the next method!
Method 2: Connection pool
So, what's the problem with the first method? In brief, the creation of a database connection is time consuming. In a standard use case where a database access is needed to perform exceptionnal operations, it does not matter. But in the case of a service like TAP whose the only goal is to execute queries on the database, there is one connection for each ADQL query. If the service is never or rarely used, no problem. Otherwise, an incredible amount of time and of resources is spent for a query which may be executed in less or equivalent time. Consequently, a solution should be found in order to avoid connection creation at each user request. This solution is called Connection Pool. It consists of creating in advance a certain amount of database connections and to deliver one for each ADQL query to execute. When a connection is not needed any more, it gets back into the pool instead of being closed. Simple, but efficient :-) Let's see now how to proceed!
There are at least two ways of creating a connection pool. The first is to use an external Java libraries (e.g. DBCP, BoneCP, DBPool, Smartpool). The second way is to use the connection pool provided in your JDBC driver. Most of famous DBMS provide a JDBC driver with a such ability. Since, it does not require an external library, we will then use this second method. However, in some cases, it can worth it to use an external framework ; for instance, in order to have more control, logs, etc.
So, now, a JDBC driver providing a connection pool will generally allow this feature through an object called
DataSource. After its configuration,
a connection is simply got with its function getConnection().
Once its mission finished, the connection is going back to the pool by paradoxally...closing it. Yes, the "close" function will
indeed not really close the connection but putting it back into the pool and flag it as available again. Knowing that, we can already say that
our factory function freeConnection(DBConnection)
won't change :-)
So, to sum up, in order to use this method, we need to create a class attribute of type DataSource,
to wrap a connection provided by the datasource when a database connection is asked and to destroy the pool when the TAP service is
destroyed. Finally, while using a PostgreSQL JDBC driver, our factory does look like the following (the modified lines are in bold style):
import tap.AbstractTAPFactory;
import tap.ServiceConnection;
import tap.TAPException;
import tap.db.DBConnection;
import tap.db.JDBCConnection;
import adql.translator.PostgreSQLTranslator;
import uws.service.log.UWSLog.LogLevel;
import javax.sql.DataSource;
import java.sql.SQLException;
import org.postgresql.jdbc3.Jdbc3PoolingDataSource;
public class MyTAPFactory extends AbstractTAPFactory {
private final DataSource ds;
public MyTAPFactory(final ServiceConnection serviceConn){
super(serviceConn);
// Create and configure a DataSource with a maximum of 10 connections:
Jdbc3PoolingDataSource pgDs = new Jdbc3PoolingDataSource();
pgDs.setDataSourceName("myFirstDatasource");
pgDs.setServerName(DB_SERVER);
pgDs.setDatabaseName(DB_NAME);
pgDs.setUser(DB_USER);
pgDs.setPassword(DB_PWD);
pgDs.setMaxConnections(10);
ds = pgDs;
}
public DBConnection getConnection(final String connID) throws TAPException{
try{
return new JDBCConnection(ds.getConnection(), new PostgreSQLTranslator(), connID, service.getLogger());
}catch(SQLException e){
throw new TAPException("Can not create a database connection!", e);
}
}
public void freeConnection(final DBConnection dbConn){
try{
((JDBCConnection)dbConn).getInnerConnection().close();
}catch(SQLException e){
service.getLogger().logTAP(LogLevel.WARNING, dbConn, "CLOSE_CONNECTION", "Can not close the connection!", e);
}
}
public void destroy(){
((Jdbc3PoolingDataSource)ds).close();
}
}
DB_SERVER, DB_NAME, DB_USER and DB_PWD
must be either replaced by their respective value or they must reference class attributes (preferably constants).
If the JAR file of your JDBC driver is in one of the locations listed above, your Web Application Server may already load the driver automatically. If it is not the case, it will be of course needed to add the following line before the creation of the datasource in the constructor of the factory:
Class.forName(DRIVER_FULL_NAME); // e.g. org.postgresql.Driver
Method 3: JNDI + Tomcat connection pool
This third method is a nice alternative to the second method. It is also using the notion of DataSource, but the creation and configuration of this latter is more integrated in your Web Application configuration. This time, all the parameters will be written in an XML file and the datasource will be stored in JNDI. In brief, JNDI is a kind of yellow page of Java objects: objects are inserted inside it, each with a name or key allowing us to fetch the object whenevever we need it.
When declaring the datasource, we still have the possibility to use the same JDBC driver's DataSource which implement a connection pool. But it is also possible to use the connection pool of your Web Application Server, if it already embeds one, like Tomcat. Generally while using the Web Application Server's connection pool is better in term of visibility and documentation: the additionnal parameters are indeed better documented. That's why we will do so in this third method.
Considering our use case, the Web Application Server is Tomcat and the database is PostgreSQL. So, the files to modify are the following:
<Context> <Resource name="jdbc/postgres" auth="Container" type="javax.sql.DataSource" driverClassName="org.postgresql.Driver" url="jdbc:postgresql:DB_NAME" username="DB_USER" password="DB_PWD" maxActive="10" /> </Context>
<web-app ...> ... <resource-ref> <description>postgreSQL Datasource example</description> <res-ref-name>jdbc/postgres</res-ref-name> <res-type>javax.sql.DataSource</res-type> <res-auth>Container</res-auth> </resource-ref> ... </web-app>
import tap.AbstractTAPFactory;
import tap.ServiceConnection;
import tap.TAPException;
import tap.db.DBConnection;
import tap.db.JDBCConnection;
import adql.translator.PostgreSQLTranslator;
import uws.service.log.UWSLog.LogLevel;
import javax.sql.DataSource;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import java.sql.SQLException;
public class MyTAPFactory extends AbstractTAPFactory {
private final DataSource ds;
public MyTAPFactory(final ServiceConnection serviceConn) throws TAPException{
super(serviceConn);
// Fetch the datasource from JNDI:
try{
InitialContext cxt = new InitialContext();
ds = (DataSource)cxt.lookup("java:/comp/env/jdbc/postgres");
if (ds == null)
throw new TAPException("Data source not found!");
}catch(NamingException ne){
throw new TAPException("Can not load the JNDI context!", ne);
}
}
public DBConnection getConnection(final String connID) throws TAPException{
try{
return new JDBCConnection(ds.getConnection(), new PostgreSQLTranslator(), connID, service.getLogger());
}catch(SQLException e){
throw new TAPException("Can not create a database connection!", e);
}
}
public void freeConnection(final DBConnection dbConn){
try{
((JDBCConnection)dbConn).getInnerConnection().close();
}catch(SQLException e){
service.getLogger().logTAP(LogLevel.WARNING, dbConn, "CLOSE_CONNECTION", "Can not close the connection!", e);
}
}
public void destroy(){ /* The DataSource will be destroyed by Tomcat. */}
}
4. DB user permissions
Some words about the way the database is accessed by the TAP Library...
Most of the time, only a read-only access to the database is needed. But 2 operations may require a write access: upload and metadata update. Both may not be used, and have a limited scope of action. Here are some useful information about these actions:
| Action | When? | What is written? | How to disable/avoid it? |
|---|---|---|---|
| Upload | At each upload, if and only if the UPLOAD capability is enabled. | If the database schema TAP_UPLOAD does not exist, it is created.
Then, the uploaded table is created in the database, filled, queried and finally destroyed.
The created table is not supposed to live longer than the time of the TAP query. |
Disable the UPLOAD capability (see III.4. Service limits). |
| Metadata update | When calling
DBConnection.setTAPSchema(TAPMetadata). In other words, when TAP metadata do not come
from the database schema TAP_SCHEMA, but from an external source
(cf II.7. List data to publish). |
This action will first drop all the tables inside the database schema TAP_SCHEMA,
if it exists. Then, all the tables defined in the given
TAPMetadata are created
in the schema TAP_SCHEMA (which is created if missing).
If some standard tables and columns defined in the
TAP Recommendation 1.0 are
missing, this function adds them automatically. |
Do NOT use
DBConnection.setTAPSchema(TAPMetadata). |
Consequently, if you want to use one (or both) of these features, adapt the rights of the used database user.
Basically, write permissions should be put only of the database schemas TAP_UPLOAD (or to allow the
creation of schemas in the DB if this schema does not already exist) and TAP_SCHEMA.
II. Service description
Now, using our factory implementation, the TAP service will be able to interact with the database. So, let's concentrate on the description of this service, that's to say the TAP metadata, the output formats and limits, the upload, the log file(s), etc...
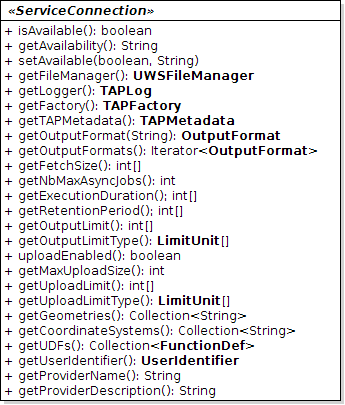
A such description is actually provided by an interface that we are going to implement:
ServiceConnection. You can see beside that, as
with the factory, a lot of functions must be defined. However, unlike the factory, here no abstract implementation
can be provided and so we will have to write all of these functions. But, no worry, most of them are really quick
to understand and to write.
Theoretically, the first function to start implementing is
getFactory().
Thus, the link between the class we have just finished to create and the service description will finally exist and the service will really
be able to access the database.
Unfortunately, as you have surely noticed while writing it, the factory uses the
ServiceConnection, especially in its constructor where a not-NULL instance
must be absolutely given. Then, you have also seen the usage of the logger. Basically, the factory needs the ServiceConnection at its
creation only to log messages (e.g. error, warnings or just info). So the factory should be created just after the initialization of the
service logger.
Of course, other functions of the factory may not ask only the logger to the ServiceConnection. However, these functions are called only to create an object and most generally when an ADQL query must be executed. Except for a DBConnection creation, ServiceConnection will never use the factory during the initialization, but in order to prevent any other function call related to a service activity, we will merely disable the service while its initialization. Thus no ADQL query can be executed. Then, we will finally enable it at the end of the servlet initialization.
In brief, setting the availability flag of the service must be the real first thing to do. Then, as said previously, the logger must be set. But, here again things are not so simple. Indeed, by default, logs are files (unless you provide a different implementation). So the file storage must be configured before the logger.
Well....all these explanations may seem a little confusing. So, let's sum up in which order we should configure the different aspects of the service:
- Availability (in order to disable the service until the servlet initialization is complete)
- File storage (because needed for the logger)
- Logger (because may be needed for any of the following configurations)
- Link with the factory (because may be needed to get/set the TAP metadata)
- TAP metadata (the TAP service could not execute ADQL queries on the database without any info about the available DB schemas, tables and columns)
- Result formats (e.g. VOTable)
- Service limits (e.g. output, upload, job duration, job destruction)
- Some ADQL restrictions (i.e. geometries, coordinates systems, udf)
- User identification
- Service provider
So, now, let's start concretely the implementation of the class ServiceConnection which we
will name "MyServiceConnection"!
import tap.ServiceConnection;
public class MyServiceConnection implements ServiceConnection {
public MyServiceConnection(){}
}
1. Availability
As said above, the first thing to do is to disable the whole service while its initialization is not finished. Thus, no user can execute ADQL queries while the service is not fully operational.
3 functions of the interface deal with the availability of the service:
isAvailable()tells whether the service is available or not. This function is used by the library in order to forbid or not access of the executive resources (i.e./syncand/async).getAvailability()gives more information about the current status of the service.setAvailable(boolean, String)enables/disables the service. The second parameter is the message which will be returned by the functiongetAvailability().
These functions are classic getters and setter. So, we need to create two class attributes: a boolean to represent the availability of the service and a string to store the description of the service status. And what is really important at this stage is to set them a default value which disables the service and explains that the service is currently initializating itself.
In few lines of code, here is what we have just explained:
import tap.ServiceConnection;
public class MyServiceConnection implements ServiceConnection {
private boolean available = false; // => service disabled by default!
private String availability = "Service not yet ready! Initialization in progress...";
public MyServiceConnection(){}
public final boolean isAvailable(){
return available;
}
public final String getAvailability(){
return availability;
}
public final void setAvailable(final boolean isAvailable, final String explanation){
this.available = isAvailable;
this.availability = explanation;
}
}
2. File storage
While running, a TAP service writes the following types of file:
- logs,
- asynchronous jobs backup,
- queries results,
- job errors,
- and uploaded files (only if the UPLOAD capability is enabled).
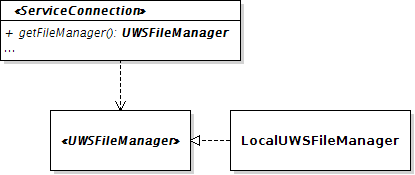
Their input and output are managed by a single class which must implement the interface
UWSFileManager.
A default implementation of this interface is already provided:
LocalUWSFileManager.
As suggested in its name, this class lets access to the local file system. While using one of its instances, all files
listed above will be stored in a single directory specified in parameter of its constructor.
A storage in a VOSpace could be a good remote
alternative for at least queries' results, job errors and uploaded files. Currently, the library does not provide a
UWSFileManager
able to access a VOSpace. So, while waiting for it and if you are interested by a such ability, you could implement this
interface yourself. This implementation could for instance stores some files (e.g. results, errors, uploads) in a VOSpace and
the others (e.g. logs, backups) in the local file system.
In the context of this Getting Started, and more generally speaking, the local file system is far enough. So, here is how we simply configure and use it:
import tap.ServiceConnection;
import java.io.File;
import uws.UWSException;
import uws.service.file.UWSFileManager;
import uws.service.file.LocalUWSFileManager;
public class MyServiceConnection implements ServiceConnection {
...
private final UWSFileManager fileManager;
public MyServiceConnection() throws UWSException{
// 1. Build the file manager:
fileManager = new LocalUWSFileManager(new File("ServiceFiles"));
}
...
public UWSFileManager getFileManager(){
return fileManager;
}
}
3. Logger
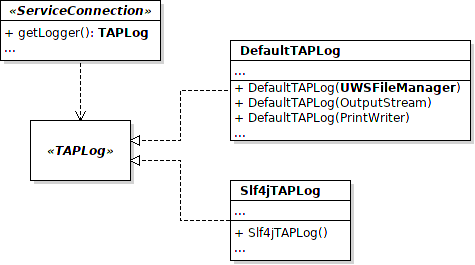
Once the file manager is configured, it is possible to create and to use a logger. This one will be very helpful for you and the library in order to debug errors and warnings.
As for the file manager, an object implementing an interface must be created. Here the interface is:
TAPLog. The default implementation provided by the library is merely called:
DefaultTAPLog. The only needed parameter is a stream or a
UWSFileManager. Since v2.3, it is also
possible to manage logs with any mechanism supporting
SLF4J (e.g.
JUL,
Log4J,
LogBack) thanks to the class
Slf4jTAPLog.
Below is an example of the default logger creation and integration in our
ServiceConnection:
...
import tap.log.TAPLog;
import tap.log.DefaultTAPLog;
public class MyServiceConnection implements ServiceConnection {
...
private final TAPLog logger;
public MyServiceConnection() throws UWSException{
...
// 2. Get the logger to use in the whole TAP service:
logger = new DefaultTAPLog(fileManager);
}
...
public TAPLog getLogger(){
return logger;
}
}
Of course, when you want to use this logger, you can use it directly by calling the function
ServiceConnection.getLogger().
But you should also know that several objects of the library let access to the same logger with a shortcut function - usually
also named getLogger().
4. Set the factory
Now, we can finally link our factory defined in I. Set database access with our
ServiceConnection.
As for the logger, the creation and integration of the factory is really straightforward, as you can see below:
...
import tap.TAPFactory;
import tap.TAPException;
import tap.db.DBException;
public class MyServiceConnection implements ServiceConnection {
...
private final TAPFactory factory;
public MyServiceConnection() throws TAPException, DBException, UWSException{
...
// 3. Build the factory:
factory = new MyTAPFactory(this);
}
...
public final TAPFactory getFactory(){
return factory;
}
}
5. List data to publish
In a TAP service, all schemas, tables and columns that can be queried in an ADQL query must be listed and should be a minimum described. This list and descriptions are called metadata. A TAP client can get them in two ways:
- by requesting in HTTP-GET the resource
/tables. - by querying the tables of the schema
TAP_SCHEMA,
Both methods must return exactly the same information. These latters are described in details by the IVOA in the TAP Recommendation 1.0, section 2.6 Metadata and TAP_SCHEMA, p.21-24.
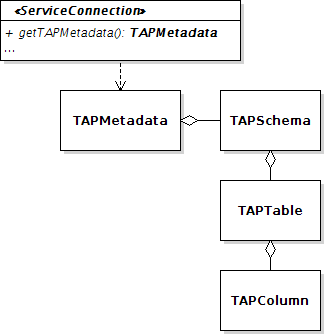
In the TAP Library, they are represented by
TAPMetadata
which gathers metadata about the published schemas, tables and columns, each represented by a Java class as shown beside.
A such object must be provided by
ServiceConnection.getTAPMetadata().
Thus the library can deal with names and types while checking the ADQL queries but also to include the metadata of
all returned columns in a resulting VOTable.
So, the goal of this step is to create an instance of this class with the list of all DB objects you want to publish.
The simplest method if obviously to build TAPMetadata
by adding one by one every TAPSchema,
TAPTable and
TAPColumn. But if you have a lot of them, it may be a little
long, unpleasant and may generate some compilation errors due to typing mistakes. The two following alternatives, based on
the two methods usable by a TAP client to get the metadata, are proposed to the developers:
- Use an XML file: here, as well, the XML file must contain information about all schemas, tables and columns
to publish. The XML document must be exactly the same as for the TAP resource
/tables. - Use the DB schema
TAP_SCHEMA: in brief, all the standard tables (and their standard columns) of this schema must be filled. The library will read it and extract all the information it needs.
To sum up, here are the three proposed method and how to proceed in order to use each of them:
The TAP resource /tables returns an XML document - using the XSD VOSI:tableset - listing all schemas, tables and
columns available in a TAP service. The TAP library lets parsing a such document in order to build automatically a
TAPMetadata object.
To do so you must follow the below instructions:
- write an XML document following this XML schema and listing schemas, tables and columns to publish,
Need an example?
- parse the XML file using
TableSetParser,/* Parse the XML document and get the corresponding TAPMetadata */ TAPMetadata metadata = (new TableSetParser()).parse(new File("..."); - update the database schema
TAP_SCHEMA./* Update the database - TAP_SCHEMA */ // Get a DBConnection using the factory: DBConnection dbConn = getFactory().getConnection("SetMeta"); // Update TAP_SCHEMA: dbConn.setTAPSchema(metadata); // Free the connection: getFactory().freeConnection(dbConn);
TAP_SCHEMA (recommended)
Why is it the recommended method? Because, using this method is very simple and ensures that metadata
returned by querying TAP_SCHEMA and by getting the HTTP resource /tables are exactly the same.
Here is how to proceed to use it:
-
The database schema
TAP_SCHEMAand all its standard TAP tables must exists in the databse and it must be filled with all the information about schemas, tables and columns to publish.Need an example? - The, we just have to get a connection and to call
getTAPSchema():// Get a database connection using the factory: DBConnection dbConn = getFactory().getConnection("GetMeta"); // Get the metadata from the database (schema TAP_SCHEMA): metadata = dbConn.getTAPSchema(); // Free the connection: getFactory().freeConnection(dbConn);
dbname
By default, the library consider the names given in TAP_SCHEMA tables as the name to use in ADQL queries
but also as the name of the corresponding database objects (i.e. schemas, tables, columns). However, by adding a column
named dbname in schemas, tables and columns, it is possible to tell
to the library that the name of the object is different in the database. Thus, ADQL names may be different from DB names.
If the value of the column is null (or empty), the ADQL and DB name will be identical.
Here, you have to build manually java objects corresponding to each column, table and schema you want to publish.
Once built, they must be linked each other as illustrated above. At the end, the schemas must be added inside the
TAPMetadata object.
Below is an example with the description of the standard table TAP_SCHEMA.schemas:
// Describe the schema "TAP_SCHEMA":
TAPSchema tapSchema = new TAPSchema("TAP_SCHEMA", "Schema dedicated to TAP. It contains all information about available schemas, tables and columns.", null);
// Describe the table "TAP_SCHEMA.schemas":
TAPTable schemas = new TAPTable("schemas", TableType.table, "List of schemas published in this TAP service.", null);
// Describe all the columns of "TAP_SCHEMA.schemas":
schemas.addColumn("schema_name", new DBType(DBDatatype.VARCHAR), "schema name, possibly qualified", null, null, null, true, true, true);
...
// Add "TAP_SCHEMA" inside the metadata:
TAPMetadata metadata = new TAPMetadata();
metadata.addSchema(tapSchema);
...
The TAP metadata must always contain the description of TAP_SCHEMA and its standard tables (and their standard
columns). Using the function
DBConnection.setTAPSchema(TAPMetadata)
will create any eventual missing standard tables and/or schema in the database AND in the given
TAPMetadata instance.
TAP_SCHEMA?
As seen with the column dbname mentionned for the second method, it is fairly possible to have additional columns and/or tables
inside TAP_SCHEMA. By default they are totally ignored by the library. However, you can either adapt the fetch of the metadata
(by overwriting DBConnection.getTAPSchema()) or modify
the fetched metadata afterwards.
And now, what are we going to do? Which method to apply? In this Getting Started, we choose the recommended method:
"Declaration in TAP_SCHEMA". Thus, the corresponding implementation of
getTAPMetadata() is the following:
...
import tap.metadata.TAPMetadata;
import tap.db.DBConnection;
public class MyServiceConnection implements ServiceConnection {
...
private final TAPMetadata metadata;
public MyServiceConnection() throws TAPException, DBException, UWSException{
...
// 4. Get the metadata:
DBConnection dbConn = factory.getConnection("MetaConn");
metadata = dbConn.getTAPSchema();
getFactory().freeConnection(dbConn);
}
...
public final TAPMetadata getTAPMetadata(){
return metadata;
}
}
6. List available result formats
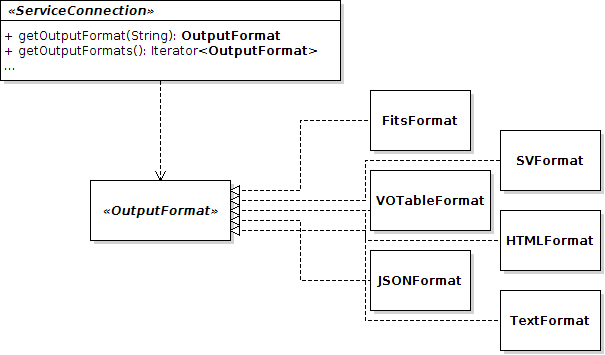
TAP lets the user choosing the format of the result. It is then up to the TAP service to propose a set of formats.
The VOTable format MUST always be in the list of proposed formats. Indeed, as requested by the TAP Recommendation, VOTable is the default format in case none are selected. Besides, the set VOTable format will also be used by the library in order to write error documents.
The TAP Library proposes several formats. Each format is represented by an object implementing
OutputFormat. Below are all formats implemented by the library:
| Format | Class |
|---|---|
| VOTable (binary, binary2, tabledata and fits serialization are possible) | VOTableFormat |
| FITS | FITSFormat |
| SV (Separated Value ; TSV, CSV or a SV with another given separator) | SVFormat |
| JSON | JSONFormat |
| HTML (just the "table" node) | HTMLFormat |
| Plain text (nice array presentation) | TextFormat |
Once you have chosen the format you want for your TAP service, you must build a list or any other representation
of your choice in which all formatters (i.e. instances of OutputFormat)
will be listed. Then, the 2 following functions must be implemented in order to provide them when needed:
getOutputFormat(String)which must return a formatter matching to the given format MIME type or name/alias (or any other expression you want to support).getOutputFormats()returning the full list of all available format/formatters.
Now, in this Getting Started, our TAP service must propose all formats implemented by the library. So, here is the following formats' configuration:
...
import java.util.List;
import java.util.ArrayList;
import java.util.Iterator;
import tap.formatter.OutputFormat;
import tap.formatter.VOTableFormat;
import tap.formatter.SVFormat;
import tap.formatter.TextFormat;
import tap.formatter.JSONFormat;
import tap.formatter.FITSFormat;
import tap.formatter.HTMLFormat;
import uk.ac.starlink.votable.DataFormat;
public class MyServiceConnection implements ServiceConnection {
...
private final List<OutputFormat> formats;
public MyServiceConnection() throws TAPException, DBException, UWSException{
...
// 5. List allowed output formats:
formats = new ArrayList<OutputFormat>(10);
formats.add(new VOTableFormat(this)); // VOTable (BINARY serialization) (default)
formats.add(new VOTableFormat(this, DataFormat.FITS)); // " (FITS serialization)
formats.add(new VOTableFormat(this, DataFormat.BINARY2)); // " (BINARY2 serialization)
formats.add(new VOTableFormat(this, DataFormat.TABLEDATA)); // " (TABLEDATA serialization)
formats.add(new SVFormat(this, SVFormat.COMMA_SEPARATOR, true)); // CSV
formats.add(new SVFormat(this, SVFormat.TAB_SEPARATOR, true)); // TSV
formats.add(new TextFormat(this)); // text/plain (with nice array presentation)
formats.add(new JSONFormat(this)); // JSON
formats.add(new FITSFormat(this)); // FITS
formats.add(new HTMLFormat(this)); // HTML (just the "table" node)
}
...
public OutputFormat getOutputFormat(final String format){
for(OutputFormat f : formats){
if (f.getMimeType().equalsIgnoreCase(format) || f.getShortMimeType().equalsIgnoreCase(format))
return f;
}
return null;
}
public Iterator<OutputFormat> getOutputFormats(){
return formats.iterator();
}
}
You should note that getOutputFormat(String) is
testing the format name with the MIME type, but also with its alias (called here "short mime type"). These tests are not case sensitive and should
always be. So, of course, it would have been more easy to use a Map rather than a List, but in this case, entries would
have been added for MIME types but also for their alias. Besides, case insensitive research would have not been possible.
7. Service limits
The goal of a TAP service is to execute several queries simultaneously. It should then ensure constantly as much availability as possible.
To help in this task, the following limits can be set in ServiceConnection:
| Limit | Description | Function | Value in this Getting Started |
|---|---|---|---|
| Fetch size | This lets retrieves a query result in several bunches of rows. The size of these bunches is set by this parameter. It must an integer array whose each value must be > 0 (while a ≤ 0 value means to wait for the whole data set before sending it) ; [0] is for asynchronous queries and [1] for synchronous ones. | int[] getFetchSize() |
null (wait for the whole data set) |
| Maximum number of asynchronous jobs | integer > 0 (≤0 means unlimited) | int getNbMaxAsyncJobs() |
30 |
| Execution duration | Default and maximum duration in seconds. This limit is represented by an array of 2 integers, whose a value ≤ 0 means unlimited: [0]=default, [1]=maximum | int[] getExecutionDuration() |
{600, 3 600} (default: 10 minutes, max: 1 hour) |
| Retention period | Default and maximum period - in seconds - while an asynchronous query can be kept on server side. In other words, it is the
duration between the creation and the destruction of a job. This limit is represented by an array of 2 integers, whose a value ≤ 0 means unlimited |
int[] getRetentionPeriod() |
{3 600, 86 400} (default: 1 hour, maximum: 1 day) |
| Output limit | Default and maximum limit on the number of maximum result rows. This limit is represented by an array of 2 integers, whose a value ≤ 0 means unlimited. The type of limit can only be LimitUnit.rows
(it is indeed the only one supported by the library for the moment). |
int[] getOutputLimit(); LimitUnit[] getOutputLimitType(); |
{1 000, 10 000} {LimitUnit.rows, LimitUnit.rows} (default: 1 000 rows, maximum: 10 000 rows) |
| Upload enabled? | By setting this attribute to false, the upload capability of the TAP service is disabled. No HTTP request with
upload will be accepted. |
boolean uploadEnabled() |
true |
| Maximum upload size | Maximum size of an HTTP multipart request. That means the sum of the HTTP header and all the parameters (all files and binaries
included). This size is expressed in bytes and MUST BE > 0 (any negative value will throw an exception) |
long getMaxUploadSize() |
1024 (1MB) |
| Upload limit | Default and maximum limit for each uploaded table, in bytes or rows. This limit is represented by an array of 2 integers, whose a value ≤ 0 means unlimited. The type of limit can be LimitUnit.rows or
LimitUnit.bytes. |
long[] getUploadLimit(); LimitUnit[] getUploadLimitType(); |
{1000, 2000} {LimitUnit.rows, LimitUnit.rows} (default: 1 000 rows, maximum: 2 000 rows) |
The corresponding implementation in our Getting Started is then as simple as following:
...
public class MyServiceConnection implements ServiceConnection {
...
/* LIMITS */
// Fetch size:
private final int[] fetchSize = null;
// Asynchronous Jobs:
private final int maxAsync = 30;
// Execution Duration:
private final int[] executionDuration = new int[]{600,3600};
// Job Destruction:
private final int[] retentionPeriod = new int[]{3600,86400};
// Output:
private final int[] outputLimit = new int[] { 1000, 10000};
private final LimitUnit[] outputLimitType = new LimitUnit[]{LimitUnit.rows, LimitUnit.rows};
// Upload:
private final boolean uploadEnabled = true;
private final long maxUploadSize = 1000000L;
private final long[] uploadLimit = new long[] { 1000L, 2000L};
private final LimitUnit[] uploadLimitType = new LimitUnit[]{LimitUnit.rows,LimitUnit.rows};
...
public int[] getFetchSize() { return null; }
public int getNbMaxAsyncJobs() { return maxAsync; }
public int[] getExecutionDuration() { return executionDuration; }
public int[] getRetentionPeriod() { return retentionPeriod; }
public int[] getOutputLimit() { return outputLimit; }
public LimitUnit[] getOutputLimitType(){ return outputLimitType; }
public boolean uploadEnabled() { return uploadEnabled; }
public long getMaxUploadSize() { return maxUploadSize; }
public long[] getUploadLimit() { return uploadLimit; }
public LimitUnit[] getUploadLimitType(){ return uploadLimitType; }
}
8. ADQL quick fix
Since version 2.3, the TAP library has a feature able to quickly attempt to fix an ADQL query. This is effective only when the ADQL query execution fails. The TAP service will try to fix it automatically and then will try again to execute it.
Considering this feature may alter the input ADQL query of the user, it is generally a good idea to disable this feature at first:
...
public class MyServiceConnection implements ServiceConnection {
...
public boolean fixOnFailEnabled(){ return false; }
}
9. ADQL restrictions
In this class, it is also possible to set few, but interesting, restrictions on the input ADQL queries. You can indeed specify which coordinate systems, geometrical functions and UDFs your TAP service must support.
Geometrical functions
The geometrical functions are the ADQL functions which represent or manipulate the geometries like boxes, circles and polygons. Here is the full list of them:
- AREA
- BOX
- CENTROID
- CIRCLE
- CONTAINS
- COORD1
- COORD2
- COORDSYS
- DISTANCE
- INTERSECTS
- POINT
- POLYGON
- REGION
In ServiceConnection,
the function getGeometries()
lets you give a restricted list of geometrical functions to allow. It must return a list containing string items whose each
must be the name (case insensitively) of the ADQL geometrical function to allow.
In this Getting Started, all geometrical functions should be allowed. Thus, the function will return
NULL (meaning "no restriction" ~ "allow all geometries").
Coordinate systems
In ADQL, a coordinate system must follow the syntax specified by STC-S. Basically, a coordinate system according to STC-S has the following syntax:
[Frame [ReferencePosition [Flavor]]].Items between brackets are optional. Thus, a coordinate system may be empty or may contain 1 to 3 items. When an empty string is specified, the coordinate system of the stored data is used.
STC lists a lot of values for each of these parts. However, TAP limits them to the following values:
- Frame:
ICRS,J2000,FK4,FK5,ECLIPTIC,GALACTICandUNKNOWNFRAME - RefPos:
BARYCENTER,GEOCENTER,HELIOCENTER,LSR,TOPOCENTER,RELOCATABLEandUNKNOWNREFPOS - Flavor:
CARTESIAN2,CARTESIAN3andSPHERICAL2
In the library, you can specify which coordinate systems your TAP service must support with the function
getCoordinateSystems().
If an ADQL query containing a coordinate system different from these specifications is submitted, the TAP service will
then reject it.
To specify allowed coordinate systems, you have to provide a list whose each item is
a kind of regular expression. On the contrary to ADQL, each part must be present.
In brief, a string of exactly 3 parts (in the order: Frame RefPos Flavor) must be provided.
Each part can be either *, a single value, or a list of values - with the syntax
'(' value1 ('|' value2)* ')' (e.g. "(ICRS|J2000)" ; only 1 item like "(ICRS)"
is also accepted).
We specify in our use case that only queries using ICRS are allowed. So in this Getting Started, we just limit the Frame as followed:
ICRS * *
- NULL => ALL possible values are allowed.
- empty list => NONE of the possible values are allowed ; any value written in an ADQL query will be rejected.
- a non-empty list of valid value(s) => restricted list of values ; any value different from the one listed here - case insensitively - written in an ADQL query will be rejected.
User Defined Functions
Being an extensive language, ADQL lets define new functions, called User Defined Functions - UDFs. Thus, the library lets also add such functions. However, the operation is not as straightforward as for the coordinate systems and geometrical functions.
Actually, it depends of how the ADQL function - the UDF - will be translated. We can distinguish 2 cases:
a. If the name and signature of the function is the same in ADQL and in your DBMS, you just have to declare
it in ServiceConnection by respecting the syntax used for the
TAP resource /capabilities.
The TAP resource /capabilities gives several information to the service users, such as the available
languages, the allowed ADQL geometries but also the list of all available User Defined Functions. In this resource,
the functions signature is a simple string with a syntax defined by the following grammar introduced in
TAPRegExt Recommendation 1.0 (section
2.3. Languages Supported):
signature ::= <funcname> <arglist> "->" <type_name>
funcname ::= <regular_identifier>
arglist ::= "(" <arg> { "," <arg> } ")"
arg ::= <regular_identifier> <type_name>
Then, the signature must be given to the static function
FunctionDef.parse(String), which
will parse the string and convert it into a function definition.
Example:
FunctionDef.parse("rtrim(txt String) -> String");
b. If you want a name or signature different in ADQL or if the ADQL function must be replaced by other
SQL instructions, a translation of this new function must be provided. This must be done by providing an extension of
UserDefinedFunction in addition
of the function signature. So concretely the declaration is very similar to the first case ; there is just an
additional step: set the corresponding Java representation.
Example:
FunctionDef udf = FunctionDef.parse("foo() ->; varchar");
udf.setUDFClass(MyFooFunction.class);
In this Getting Started, we will just allow the usage of few SQL functions in ADQL, by creating a list with the following function definitions:
random() -> doublertrim(txt String) -> Stringrpad(txt varchar, len int, fill varchar) -> VARCHARinitcap(txt varchar) -> VARCHAR
String (Java) andVARCHAR (DB)
in the above definitions.
Finally, here is the corresponding source code of these three elements:
...
import adql.db.FunctionDef;
import java.util.Collection;
import adql.parser.ParseException;
public class MyServiceConnection implements ServiceConnection {
...
// List of allowed coordinate systems:
private final List<String> coordinateSystems;
// List of all user defined functions:
private final List<FunctionDef> allowedUdfs;
public MyServiceConnection() throws TAPException, DBException, UWSException{
...
// 6a. Coordinate systems:
coordinateSystems = new ArrayList<String>(1);
coordinateSystems.add("ICRS * *");
// 6b. UDFs (User Defined Functions):
allowedUdfs = new ArrayList<FunctionDef>(4);
try{
allowedUdfs.add(FunctionDef.parse("random() -> double"));
allowedUdfs.add(FunctionDef.parse("rtrim(txt String) -> String"));
allowedUdfs.add(FunctionDef.parse("rpad(txt varchar, len int, fill varchar) -> VARCHAR"));
allowedUdfs.add(FunctionDef.parse("initcap(txt varchar) -> VARCHAR"));
}catch(ParseException pe){
throw new TAPException("Can not initialize the TAP service! There is a wrong UDF definition: " + pe.getMessage(), pe);
}
}
...
public Collection<String> getCoordinateSystems(){
return coordinateSystems;
}
public Collection<String> getGeometries(){
return null; /* => ALL */
}
public Collection<FunctionDef> getUDFs(){
return allowedUdfs;
}
}
10. User identification
Like in a lot of existing web services, user authentication is possible in TAP. However, since no identification/authentication
method is widely used in practice in the VO community, the library does not propose any by default. So if you want too this
ability, you would have to implement an authentication method of your choice thanks to the interface:
UserIdentifier.

Then, an instance of this class must be stored as class attribute of your
ServiceConnection. This instance must be returned by the function
getUserIdentifier(). But, of course, if you
don't want a such mechanism, this function must return NULL.
Since no user identification has been asked by our use case, we will add the following lines:
...
import uws.service.UserIdentifier;
public class MyServiceConnection implements ServiceConnection {
...
public UserIdentifier getUserIdentifier(){
return null;
}
}
11. Service provider
And finally, it now remains 2 informative functions to implement:
getProviderName: name of the person or organization providing the TAP service.getProviderDescription(): description of the provider and/or of the service. Coordinates of the provider may also be given.
The above description of these functions is purely informal, because actually, you can put here any information you want. At the end, both of them are displayed on the default home page provided by the library and is added into the header of any query result as additional INFO elements.
So, now, with the following lines, we finally finish the description of our TAP service:
...
public class MyServiceConnection implements ServiceConnection {
...
// Provider information:
private final String PROVIDER = "TAPTuto";
private final String PROVIDER_DESCRIPTION = null;
...
public final String getProviderName() { return PROVIDER; }
public final String getProviderDescription(){ return PROVIDER_DESCRIPTION; }
}
III. Write the servlet
We have now done the whole service configuration. The worst is behind us. Let's now write a servlet and declare it in our Web Application Server!
Basically, all we have to do, is to create an instance of TAP, to
initialize it with our ServiceConnection and to create an
HTTPServlet
which will forward ALL requests to the TAP object.
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import java.io.IOException;
import tap.resource.TAP;
public class MyTAPServlet extends HttpServlet {
// Object representation of the TAP service.
private TAP tap;
public void init(final ServletConfig config) throws ServletException{
try{
// 1. Create a TAP instance:
tap = new TAP(new MyServiceConnection());
// 2. Initialize its resources:
tap.init(config);
// 3. Set the service as available:
tap.getServiceConnection().setAvailable(true, null);
super.init(config);
}catch(Throwable e){
throw new ServletException("Can not initialize the TAP service!", e);
}
}
protected void service(final HttpServletRequest request, final HttpServletResponse response) throws ServletException, IOException{
// Forward the request to the TAP library:
tap.executeRequest(request, response);
}
public void destroy(){
// Free all resources attached to this TAP service (and its resources):
/* note: after this call, no resources of the TAP service can be requested. */
tap.destroy();
super.destroy();
}
}
TAP.destroy().
Take a look to the above source code to see how to use this function!
Once the servlet written, just a final step: to declare it in web.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<web-app ... >
...
<servlet>
<display-name>TAPService</display-name>
<servlet-name>TAPService</servlet-name>
<servlet-class>MyTAPServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>TAPService</servlet-name>
<url-pattern>/tap/*</url-pattern>
</servlet-mapping>
<web-app>
/*, as done at line 11. This is really important,
because otherwise, the TAP Library is not able to deal with all its resources (i.e. /sync, /async, /tables, ...) and so only the home
page would be accessible....which would be really a shame after all these efforts, no?
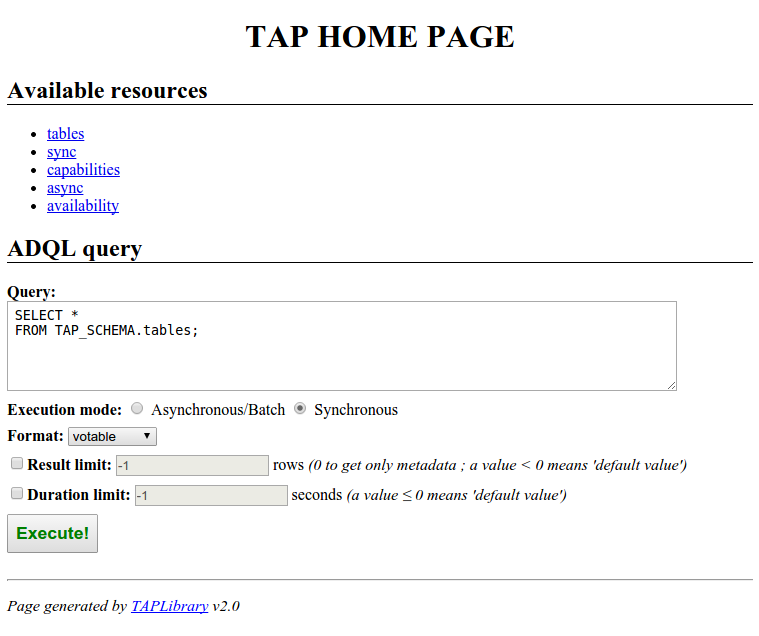
Now, you should be able to start your TAP service!
When accessing the root URL of your TAP service
in your Web Browser, you should get the following home page:
TAP.setHomePage(String)
or by extending TAP and then overwritting the function
writeHomePage(HttpServletResponse, JobOwner).
Common errors are the followings:
- the web application is NOT successfully deployed
- the URL typed in the web-browser is merely INcorrect ; it should be something like
http://localhost:8080/{webappName}/tap(where{webappName}is the name with which your web application has been deployed). - missing libraries ; should be at least put in
WEB-INF/libthe JAR file for the TAP Library and the JDBC driver - incorrect database URL, user or password.
Then, something that could help is to know that depending of what the error looks like, the error may have a different origin:
- HTML error page => returned by your Web Server Application.
First, check your dependencies. This is very common to forget to include/deploy the required libraries (e.g. JDBC driver,
TAP Library, Connection Pool). Then, the error may come from the initialization of the
TAPobject in theHttpServlet.init(...)function. If so, except if the error is obvious, you should look inside the TAP log file...it may give you a very good hint of the error origin. - VOTable error document => returned by the TAP Library. There, you have no choice, you must look inside the TAP log file.
Additionnal information may be found in the TAP service log files. Generally named service.log, this file is theoretically
in the directory you specified while creating a
LocalUWSFileManager. But of course, it depends of how you
choose to manage service files.
Anyway the log file(s) of your web application server could also help you.
If you still have no idea of the origin of the error, you can contact the developer of this library.
Finally...
We finally reach our goal in just few simple text lines! By restarting our web application server with the last modifications we should now have exactly what was specified at the beginning of this Getting Started.
Of course, more aspects of the generated TAP service may be configured or customized. For that you are encouraged to take a look at the library documentation: Documentation.