A. Parser
The ADQL parser is probably the most useful functionnality of this library. Knowing how it works will help you to customize it if needed.
1. Generated parser How to parse your query?
The ADQL parser has been generated thanks to JavaCC (Java Compiler Compiler). It is a Java parser generator which takes one grammar definition file (with the extension .jj) and generates 7 classes: (supposing the parser is called: ADQLParser)
- ADQLParser.java: the parser itself
- ParseException.java: it is an Exception thrown by ADQLParser when a grammar/syntax error is encountered
- ADQLParserTokenManager.java: the scanner/lexical analyzer
- TokenMgrError.java: it is an Error thrown by ADQLParserTokenManager when a token can not be resolved
- Token.java: represents one token as it is defined in the grammar file
- ADQLParserConstants.java: litteral values and constants
- SimpleCharStream.java: a character stream
The only class which is really interesting here is the parser: ADQLParser. With it, you can theoretically parse any part of ADQL, but here it has been written so that parsing only a whole query. Thus, using the following generated parser is very easy:

a. Create a parser
In general, you can create a parser by using the constructor without parameters. The 2 others are useful only if you want to check more structural aspects of the query or to customize the ADQL object creation.
ADQLParser parser = new ADQLParser();
- 2. Factory: to customize the objects generation,
- 3. Checker: to add your own checks to the parser.
b. Parse a query
Then, you can parse a query coming from an InputStream or stored into a String variable with the functions parseQuery(..). If the query is successfully parsed, an object of type ADQLQuery representing the given ADQL query is returned. Otherwise, a ParseException is thrown.
try{
ADQLQuery query = parser.parseQuery(adql);
}catch(ParseException pe){
System.err.println("ADQL syntax incorrect between "+pe.getPosition()+": "+pe.getMessage());
System.exit(2);
}
- B. ADQL tree: to understand the structure of the generated tree,
- 4. Exceptions: to know more about the exceptions thrown by the parser.
Automatic query fix
Since v1.5, the ADQL parser provides a new function: ADQLParser.tryQuickFix(...). This is a new feature that lets fix the most common errors while writing ADQL queries:
- replace some Unicode characters (e.g.
_,',"copy-pasted from a PDF for instance) by their UTF-8 equivalent - double-quote SQL reserved keywords (e.g.
public,date,year,user) - double-quote ADQL function names when used as table/column name/alias
(e.g.
distance,point,min) - double-quote incorrect regular identifiers for table/column name/alias
(e.g.
_RAJ2000,2mass)
Here is an ADQL query that any user would want to run but whose the parsing will immediately fail because of the starting _, the distance (which is reserved to an ADQL function) and public (which is a reserved SQL word):
SELECT id, ﹍raj2000, _dej2000, distance FROM public.myTable
Applying the function tryQuickFix(...) will produce the following query:
SELECT id, "_raj2000", "_dej2000", "distance" FROM "public".myTable
This query should now run...but only if the case is correct for the column and schema names. That that is indeed not tested by this function ; the user will still have to check that by himself.
Debug mode
By setting the debug flag to true using the function
ADQLParser.setDebug(),
every grammar rules selected by the parser will be displayed on the default output stream.
Thus, you can see which decisions have been taken by the parser in function of the read part
of the query. This could be very helpful for debugging of the parser or to better understand the
returned ADQLQuery.
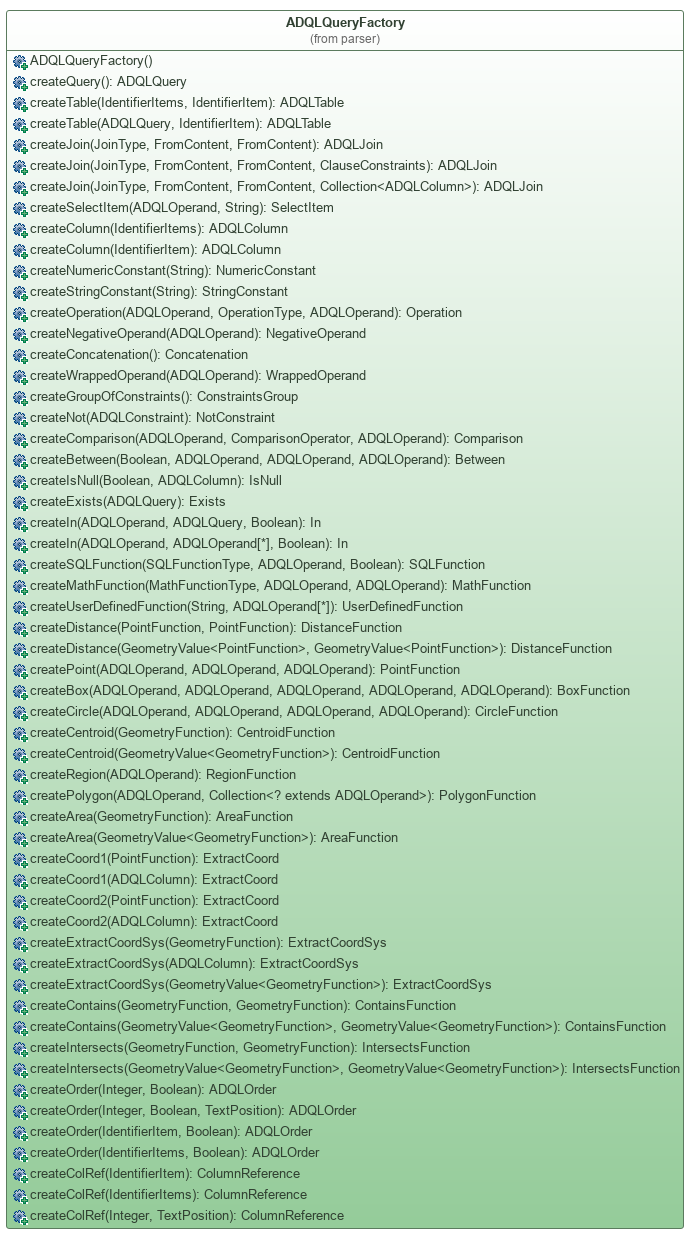
2. Factory How to customize the generated object?
To build an object representation of a given ADQL query, the parser uses a factory.
This factory has at least one function for each type of ADQL part. For instance:
- createQuery()
- creates an instance of ADQLQuery. However, by default, the generated representation is empty: no select item, no table, ... They must be added after the creation.
- createTable(IdentifierItems, IdentifierItem)
- creates an instance of ADQLTable with the full name of the table and an alias.
- createTable(ADQLQuery, IdentifierItem)
- another function to build an ADQLTable, but this time, with a sub-query as table. The second parameter is the table alias.
- createSelectItem(ADQLOperand, String)
- creates an item of the select clause (SelectItem). It could be anything: a textual or numeric constant, an operation, a concatenation, a column or a function. All of them are considered as operands for the library: hence the type ADQLOperand. The second parameter of the function is the alias of the resulting column (the corresponding column in the result of the query execution).
- ...
Identifiers
As you can see, the functions of the factory have different kinds of parameter: either a String or another type of ADQL object. But some of them use also IdentifierItems or IdentifierItem. Both are representation of ADQL identifiers. They are used to represent a column or table name. IdentifierItem is only one identifier whereas IdentifierItems is an agregate of at most 4 identifiers. So they let represent resp. a simple (i.e. "ra") or a complex identifier (i.e. "catalog.schema.AstroData.ra").
Extension
The library is designed so that a developer can customize any part of the object representation of an ADQL query. For that, he has just to extend the appropriate class and to extend the factory. By extending it you can change partially or fully the object representation generated by the parser. Once extended, you just have to provide an instance of this class to the parser at its creation:
ADQLParser parser = new ADQLParser(new MyADQLQueryFactory());
User Defined Function
ADQL allows developpers to add functions into the language: this kind of function is called "User Defined Function" (UDF).
Each time the parser encounters a function which is not part of ADQL, it considers it as a User Defined Function. Consequently it asks to the factory to create the corresponding Java representation by calling its function: createUserDefinedFunction(String, ADQLOperand[]).
By default the factory returns an instance of DefaultUDF for each unknown function and does not raise any error. Of course, all unknown functions are not always UDFs, but by default the library has no way to know which function is supported or not. The default behavior in the previous versions of the library was to raise an error for each of these functions except if a flag said to allow unknown functions...but in this case all were allowed, which is also not really better. So, this was an incomplete and not satisfying behavior.
From the version 1.3, all unknown functions are allowed and represented as said above by a DefaultUDF. Consequently, one of the two following methods can be used to check whether an unknown function is supported or not:
- 1. check after building of the ADQL tree by using a QueryChecker
- This method is described in the next part: 3. Checker.
2. extend ADQLQueryFactory and override createUserDefinedFunction(String, ADQLOperand[])-
You can see how to proceed more concretely with the following example. Suppose you want to support a UDF named
FOOhaving only one parameter of type numeric. Here would be the source code of such class:
public class FooFunction extends UserDefinedFunction { private ADQLOperand bar; public FooFunction(final ADQLOperand bar){ this.bar = bar; } public String getName() { return "FOO"; } public boolean isNumeric() { return true; } public boolean isString() { return false; } public boolean isGeometry() { return false; } public ADQLObject getCopy() throws Exception { return new FooFunction(this.bar); } public int getNbParameters() { return 1; } public ADQLOperand getParameter(int index) throws ArrayIndexOutOfBoundsException { return bar; } public ADQLOperand[] getParameters() { return new ADQLOperand[]{bar}; } public ADQLOperand setParameter(int index, ADQLOperand op) throws ArrayIndexOutOfBoundsException, NullPointerException, Exception { if (op == null) throw new NullPointerException("The function FOO requires only one parameter !"); else if (op.isNumeric()){ ADQLOperand oldOp = bar; bar = op; return oldOp; }else throw new Exception("The function FOO requires a numeric parameter !"); } public String translate(ADQLTranslator translator) throws TranslationException{ return "foo("+translator.translate(bar)+")"; } }
You should note that since version 1.3, a "translate" function must be implemented while extending UserDefinedFunction. This is a very helpful addition since it avoids extending also a translator in order to support properly the supported UDFs: all information (i.e. function name, parameters, return types and SQL translation) are now stored in the same class. All must be done now, is just to create an instance of it in the query factory:
public class MyFactory extends ADQLQueryFactory { public UserDefinedFunction createUserDefinedFunction(String name, ADQLOperand[] params) throws Exception { if (name.equalsIgnoreCase("FOO")){ if (params.length == 1){ if (params[0].isNumeric()) return new FooFunction(params[0]); else throw new ParseException("The parameter of FOO must be numeric !"); }else throw new ParseException("The FOO function must have only one parameter !"); }else throw new ParseException("Unknown ADQL function: "+name); } }
3. Checker How to include your own checks?
The parser provided in the library is configured only to check the ADQL syntax. It implies that if you want to make other verifications on the query, you must do it after the parsing and on the whole generated object representation of the query. However, the library lets you include your own checks during the parsing process...
The interface QueryChecker
The interface QueryChecker is designed to be called after the parsing of each parsed ADQL query. Its API is very simple: one method which takes the generated instance of ADQLQuery. This method is supposed to throw a ParseException if it detects an error.

The "check" function of this interface - check(ADQLQuery) - is called only for the root ADQL query. Sub-queries MUST be checked individually inside the root call of this function. Thus, it is up to the interface implementations to check or not sub-queries. For instance, the provided implementation - DBChecker - checks automatically sub-queries.
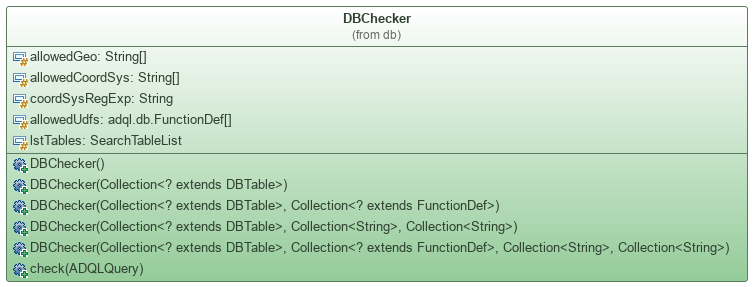
The class DBChecker
In order to check that referenced columns and tables exist in the database, you can use the class DBChecker which implements directly QueryChecker. To create an instance you must provide a list of all available tables.
In addition to check the existence of table and column references, this checker adds information into the table and column references of the given ADQLQuery. More precisely, it adds the description of the referenced items (table or column): DBTable or DBColumn. This reference can be then fetched with the function ADQLTable.getDBLink() or ADQLColumn.getDBLink().
An example of use of the DBChecker is available in the part Getting Started.
Table & Column description
As said just before, the DBChecker requires a list of all available tables. Theses tables must be described by any implementation of the interface DBTable. That's how the catalog, the schema and the name of the table can be known by the checker.
For different reasons, you may decide that the ADQL name (name of the column/table written in the ADQL query) is different from the DB name (name of the column/table in the database). That's why, you have 2 functions to return the name of a table: getADQLName() and getDBName().
For each DBTable, a list of all columns it contains must be provided. As for the table, there is also an interface to describe columns: DBColumn. Again, you must specify its name in ADQL and in the database.
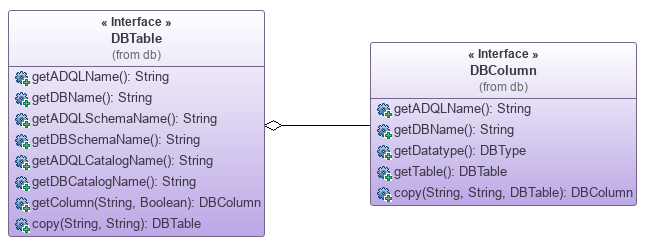
- The library includes a default implementation of DBColumn and DBTable: DefaultDBColumn and DefaultDBTable.
-
The TAP Library provides
an XML parser in order to convert an XML document listing and describing a
set of schemas, tables and columns. This kind of document is returned by the
resource
/tablesof a TAP service. The parser provided by the TAP library is named TableSetParser and uses extensions of DBTable and DBColumn: TAPTable and TAPColumn.
With a query checker it is then possible to check and/or to change every part of a parsed ADQL query. As just said above, DBChecker has originally been designed in order to check table and column references. However, since version 1.3 of the library, it is also able to check more. Below are listed 3 verifications which can be performed by this checker implementation:
User Defined Functions
As said previously, another way to declare a UDF is by using a DBChecker. You can see in the above UML class diagram of this class that 2 constructors let provide a list of objects of type FunctionDef whose the class content is shown below:
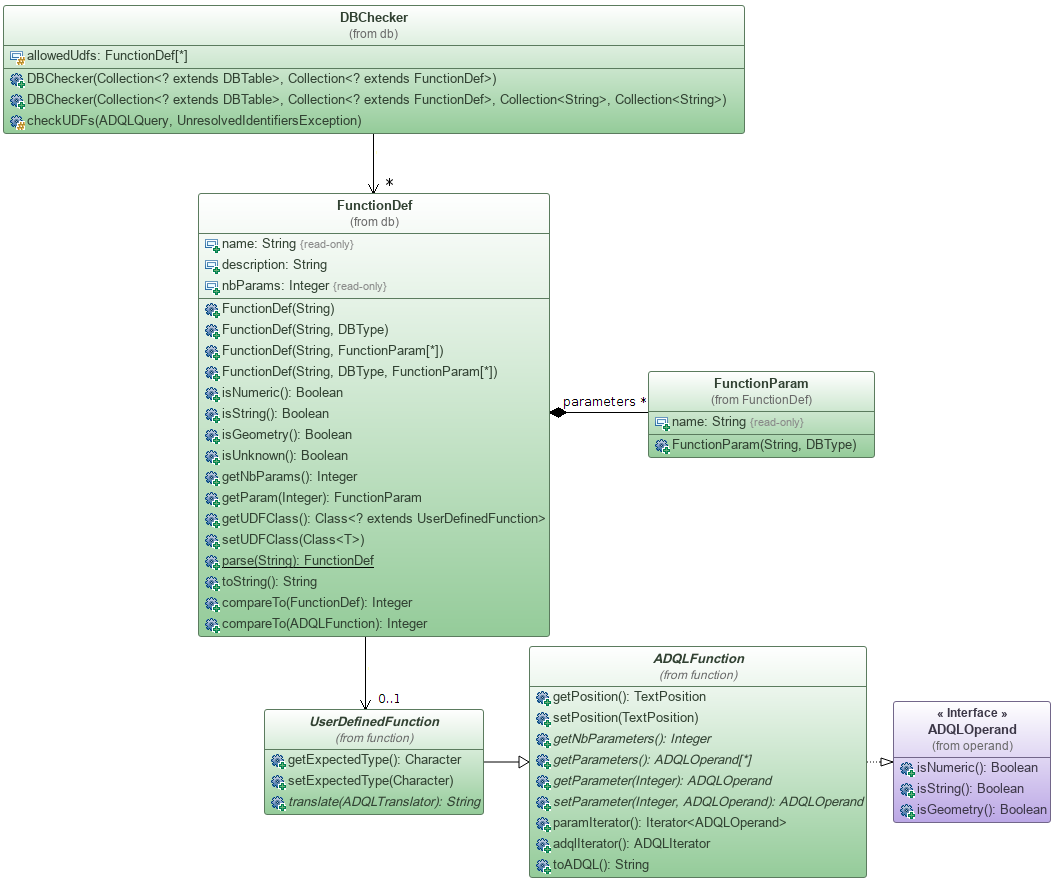
With a such list of objects, the checker will be able to check every DefaultUDF found inside the ADQL query tree. First, it will search all of them. Second, for each of them, it will try to find a match based on the functions signature (i.e. name + parameters' types) in the given list of UDFs.
no match In case no match is found an error is associated with this function and the checker continues to try resolving the other found DefaultUDFs. Thus, when the whole parsing process is finished, all unresolved functions are reported, and not just the first one.
match When the checker find a match it associates the DefaultUDF instance with the object returned by FunctionDef.getUDFClass() if any is set. This UDF class is actually very important for the translation of the UDF. Indeed, the translation of any instance of UserDefinedFunction is performed by itself thanks to its function translate(ADQLTranslator). So, if the DefaultUDFs are not replaced by another UserDefinedFunction, there will be no translation (i.e. the SQL function will look exactly like in ADQL).
DBChecker does not try to find for other matches in the given list when one has been found. It stops its research at the first found UDF. It then assumes that all listed functions have a unique signature and this must be ensured by you before providing this list, otherwise only the first FunctionDef of the list with the same signature will be used.
It is said that a list of all functions we want to allow must be provided. But since all functions must be
listed, if none are in the list, all unknown functions will be rejected.
So: an empty list means "forbid all unknown functions". Similarly, if no list is provided, then
any unknown function will be allowed: NULL means "allow any unknown function".
In case you have not noticed when looking the UML class diagram, a static function is provided by the class FunctionDef: parse(String). This function reads a string expression representing an extended function signature and returns the corresponding FunctionDef object. The string expression must respect the following simple syntax:
signature ::= <funcname> <arglist> "->" <type_name>
funcname ::= <regular_identifier>
arglist ::= "(" <arg> { "," <arg> } ")"
arg ::= <regular_identifier> <type_name>
A type can be any DBMS column's type or Java type (i.e. String and all native types (e.g. char, boolean, int)).
Here is an example of correct string expression using this syntax: trim(strToTrim VARCHAR) -> String
Coordinate systems
In the previous version of this library, it was already possible to restrict the list of allowed coordinate systems, but the syntax was too rigid: only one combination of frame, reference position and flavor was allowed. Besides, the definition had to be done in the parser using a setter function.
From the version 1.3, the declaration of allowed coordinate systems can be done ONLY in a constructor of DBChecker (or using a custom QueryChecker). As for the User Defined Functions, a list of allowed values is expected. Each item of this list must be a String expression whose the syntax is really simple and is inspired from regular expressions:
{frame} {refPos} {flavor}
Each of these items must be present. However, instead to specify one value for an item, it is possible to give a list of values with the following syntax:
({value1}|{value2}|....)
A such list may contain at least one value. Alternatively, if you want to allow all values, you can replace this whole list by
a * character.
Thus the following expressions are totally valid:
ICRS GEOCENTER CARTESIAN2* * CARTESIAN2(ICRS|FK4|FK5) * *
The same rules as for the User Defined Function applies here. If an empty list is provided, it will mean
"forbid all coordinate system specification". And, if no list (i.e. NULL) is provided, then
it will mean "allow any coordinate system".
Geometrical functions
"Geometrical functions" means here all functions introduced by ADQL and which let represent or manipulate a geometrical region. All those functions are the following:
AREA,BOX,CENTROID,CIRCLE,CONTAINS,COORD1,COORD2,COORDSYS,DISTANCE,INTERSECTS,POINT,POLYGON- and
REGION
Providing the allowed geometrical functions is really easier than the two other lists: each item of the list is a simple String corresponding to the name (case insensitive) of a function.
The same rules as for the User Defined Function and Coordinate Systems applies also here. If an empty list is provided,
it will mean "forbid all geometrical functions". And, if no list (i.e. NULL) is
provided, then it will mean "allow all geometrical functions".
4. Exceptions What are the different kind of exceptions ?
In addition to the parser, JavaCC generates also 2 classes: ParseException and TokenMgrError. Besides DBChecker also throws particular types of ParseException...
JavaCC errors
The parser generated by JavaCC works in 2 main steps:
- It reads the query and splits it into elementary items called "tokens".
- It tries to match the list of resolved tokens with the defined grammar.
Each step may interrupt the parsing. Indeed, when a token can not be resolved, a TokenMgrError is thrown. And when a succession of tokens does not match the expected grammar rule, a ParseException is thrown.
TokenMgrError

This error extends the class Error of Java. This error tells that ADQLParserTokenManager is not able to resolve the characters at the line getErrorLine() and at the column getErrorColumn(). A complete error message is provided by getMessage().
...all TokenMgrError thrown by JavaCC are immediately caught and wrapped inside a ParseException (as cause of the exception) by the ADQL Library.
Indeed, in Java Errors are supposed to be thrown only in case of very serious error. But in this ADQL parser, when a part of the query to parse can not be resolved in a token, it is not a serious error, but just a normal error saying that the query is not valid. So throwing a ParseException seems completely appropriate. Besides, it lets the user deal with only one error type instead of two.
ParseException

This exception extends the class Exception of Java. It keeps the token which causes the error and its position in the original query. It also provides a list of all expected tokens thanks to expectedTokenSequences and tokenImage. The items of expectedTokenSequences are indexes of tokenImage. Thus, you can get which tokens were expected.
This class has been slightly modified in the ADQL Library compared to what JavaCC generates. By default, this class gives only the begin line and column. That's why a full position of the error: getPosition().
Token
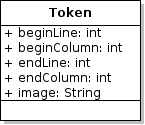
This class represents an elementary part of the ADQL grammar. As explained above, when parsed, a string is converted into a list of tokens. Then, the succession of tokens should match to the grammar defined in the .jj file.
A token can be localized by a begin line and column and an end line and column. A fifth attribute gives the parsed string corresponding to the token: image.
TextPosition

ParseException has been modified so that adding a positional information: TextPosition. With this class it is possible to indicate a position or a region in the original query.
This class is particularly useful for the errors returned by DBChecker.
DBChecker errors
As explained above, DBChecker is designed to check column and table references in the ADQL query. If a such reference can not be resolved, a ParseException is thrown.
To be more precise, what it throws is an extension of ParseException: UnresolvedIdentifiersException. This exception is a list of ParseExceptions which are most of the time UnresolvedColumnException and UnresolvedTableException. The first one is thrown when a column reference can not be resolved, whereas the second one is for an unresolved table reference. The other extensions are used when a join can not be operated because joined columns are not compatible - UnresolvedJoinException - and when a function is unknown - UnresolvedFunctionException.
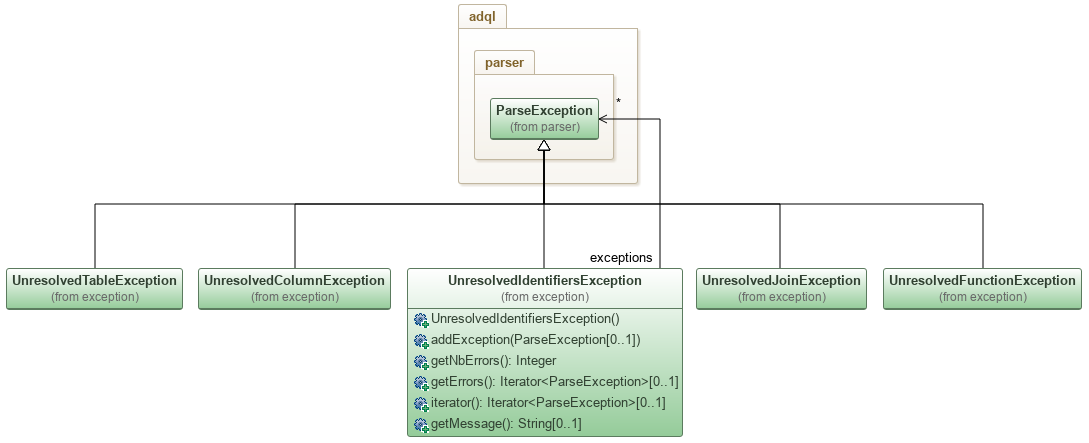
On the contrary to UnresolvedIdentifiersException which lets iterate on its list of exceptions thanks to getErrors(), the other ParseExceptions are "normal" parsing exception: a message and eventually a cause. So their usage is very simple. Here is an example of use of this kind of exception.
try{
ADQLParser parser = new ADQLParser(new DBChecker(tables));
ADQLQuery query = parser.parse(adql);
}catch(UnresolvedIdentifiersException uie){
System.err.println(uie.getNbErrors()+" unresolved identifiers:");
Iterator<ParseException> it = uie.getErrors();
ParseException ex = null;
while(it.hasNext()){
ex = it.next();
System.err.println(" * "+ex.getPosition()+": "+ex.getMessage());
}
}catch(ParseException pe){
System.err.println("ADQL syntax incorrect at "+pe.getPosition()+": "+pe.getMessage());
}
All the listed above extensions of ParseExceptions keep, most of the time, the position of the error in the original ADQL query. As you can see on the above example, this position can be got thanks to their function getPosition().