What's new?
The list of all modifications done recently on the library.
v1.5 - 20th March 2019
Add to the parser a function attempting to quickly fix an ADQL query. ...
This new function - ADQLParser.tryQuickFix(...) - fixes the most common issues with ADQL queries:
- replace Unicode confusable characters by their ASCII/UTF-8 version,
- double-quote SQL reserved words/terms (e.g.
public,year,date), - double-quote ADQL function names used a column name/alias (e.g.
distance,min,avg), - double-quote invalid regular identifiers (e.g.
_RAJ2000,2mass).
The last point is far from being perfect but should work at least for identifiers starting with a digit or an underscore, or an identifier including one of the following character:
?,!,$,@,#,{,},[,],~,^and`.It should also been noted that double-quoting a column/table name will make it case-sensitive. Then, it is possible that the query does not pass even after the double-quote operation ; the case would have to be checked by the user.
Finally, there is no attempt to fix column and table names (i.e. case sensitivity and/or typos) using tables/columns list/metadata. That could be a possible evolution of this function or an additional feature to implement in the parser.
For instance, here is an ADQL query that any user would want to run but whose the parsing will immediately fail because of the starting
_, thedistance(which is reserved to an ADQL function) andpublic(which is a reserved SQL word):SELECT id, _raj2000, _dej2000, distance FROM public.myTableApplying the function
tryQuickFix(...)will produce the following query:SELECT id, "_raj2000", "_dej2000", "distance" FROM "public".myTableThis query should now run (if the case is correct for the column and schema names...but that is not tested by this function ; the user will still have to check that by himself).
Fix the SQL translation of ORDER BY's column identifiers of aliased tables. ...
Since commit 3d96c9d908624f09e64eae5cf18e72fafbefaf80 aliases put on a table without double quotes are put in lower case and then double quoted. This modification was not effective for ORDER BY's column identifiers.
See on GitHub
Fix SQL translation of concatenation for MS-SQL and MySQL ...
In Oracle and Postgre, the concatenation is performed with the operator
||, but MySQL uses instead the functionCONCAT(...)while MS-SQLServer uses the operator+.See on GitHub
Upgrade to Java 7 ...
See on GitHub
v1.4 - 26th February 2018
Upgrade the JavaCC version to 6.0 ...
See on GitHub: 005fc62... and 42cb5bb...
Translation for MS SQL Server ...
This new translator is named: SQLServerTranslator. Because the management of JOINs is a bit different in SQL Server, the ADQLQueryFactory and the object representation of the INNER and OUTER JOIN have been extended.
Because no equivalent of PgSphere or Q3C exists for SQL Server, this translator does NOT have any implementation for ALL the geometrical functions.A special thanks to vforchi and theresadower for having shared their implementation and experience of MS-SQLServer.See on GitHub for its creation, but further modifications have been done on SQLServerTranslator (look at its history to get all related commits)
Translation for MySQL + Better support of MySQL DBs ...
In MySQL, a schema is not part of a database but is a database. For that reason,
JDBCConnectioncan not check the existence of every declared schemas ; it will always considered they exist. If not, an error from the database will be thrown.Additionally, an appropriate
ADQLTranslatorhas been created:MySQLTranslator.Support
J2000as valid STC-S's frame ...HINT in errors when a reserved word is encountered ...
The ADQL parser has been slightly changed in order to provide a more precise location of the REAL wrong part of the query when an error is thrown.
Before this fix, if an ADQL or SQL reserved word (e.g. 'point') was encountered outside of its normal syntax (e.g. 'point' not followed by an opening parenthesis), the next token was highlighted instead of this one. Hence a confusing error message.
For instance, the following ADQL query:
SELECT point FROM aTable
returned the following error message:
Encountered "FROM". Was expecting: "("Now, it will return the following one:
Encountered "point". Was expecting one of: "*"
"TOP" [...] (HINT: "point" is a reserved ADQL word. To use it as a column/table/schema name/alias, write it between double quotes.) This error message highlights exactly the source of the problem and even provide to the user a clear explanation of why the query did not parse and how it could be solved.
See on GitHub: db0dfda... and fe4c3e9...
TokenMgrErrornow wrapped insideParseException...A
TokenMgrErrorwas thrown when an unexpected character was encountered by the parser. This is the default behavior of the parser generated by JavaCC.However, as raised by Zarquan and bourgesl in the GitHub issue #17, in the Java language, throwing an Error should be reserved for very serious errors. That's why, any
TokenMgrErrorthrown by the parser is immediately caught and wrapped inside aParseExceptionwith the appropriate position in the query.Move joined columns of a
NATURAL JOINorJOIN...USINGin first position ...Add missing position for all objects of a generated ADQL tree ...
Some parsing exceptions (especially for functions or JOIN) did not specify the position of the error in the given ADQL query. It was also the case of several ADQL tree objects such as: BETWEEN, IN, EXISTS, operations, ... Now, the position is always given when possible.
See on GitHub: 163ec17... and 118cd72...
Allow extension of
NumericConstantandSearchTableList...See on GitHub: c142215... and 1a3bd2b...
Addition of a new DB datatype:
UNKNOWN...This datatype is set automatically to a column (DBColumn) or a function's return type (FunctionDef) when the type can not be determined. For a column or function with this datatype the function isUnknown() will return
true. On the contrary, all the following functions will returnfalse: isNumeric(), isBinary(), isString() and isGeometry().This rule does not apply for any extension of ADQLOperand. Since the general type (i.e. numeric, string or geometry) of this kind of object may be tested by a QueryChecker, it is important that an unknown type is not rejecting the query although the exact type of items is not yet known (it will be known only while executing the query in database). Thus, if the type of an ADQLOperand is unknown all the following functions must returntrue: isNumeric, isString and isGeometry. Besides, this class does not have anisUnknown()function.See on GitHub: 37e26a1... and 271e03c...
keep the same case for undelimited column names ...
When translating into SQL, if a column was declared with no alias and was not delimited (i.e. between double quotes), the translator set an alias with the column name...but in the same case. Depending on the used database and its configuration, the different case between the alias and its references would throw an error.
For instance, the following ADQL query:
SELECT t.* FROM (SELECT (ra+ra_error) AS x, pmra AS "ProperMotion", (dec+dec_error) AS Y FROM mytable) AS t
triggered the following error with PostgreSQL:
Caused by a org.postgresql.util.PSQLException at [...] ERROR: column t.Y does not exist
because its translation in SQL was:
SELECT "t"."x", "t"."ProperMotion", "t"."Y" FROM (SELECT ("public"."mytable"."ra"+"public"."mytable"."ra_error") AS x, "public"."mytable"."pmra" AS "ProperMotion", ("public"."mytable"."dec"+"public"."mytable"."dec_error") AS Y FROM "public"."mytable") AS "t"To avoid this error, automatic aliases are always delimited and written in lower-case. Which would now look like below:
SELECT "t"."x" AS "x", "t"."ProperMotion" AS "ProperMotion", "t"."y" AS "y" FROM (SELECT ("public"."table2"."ra"+"public"."table2"."ra_error") AS "x", "public"."table2"."pmra" AS "ProperMotion", ("public"."table2"."dec"+"public"."table2"."dec_error") AS "y" FROM "public"."table2") AS "t"Multiple space characters between the tokens
ORDER/GROUPandBY...Before this correction,
ORDER BYandGROUP BYhad to be written with only one space (i.e. ' '). Now, it is perfectly allowed to write more than one space (and even any space character such as a tab or a new line) betweenORDER/GROUPandBY.Fix automatic name of some operands (e.g. +, -, ...) ...
The idea is to get rid of special characters such as '-', '+' , '(', ... in the columns name of the output table.
Infinite loop when wrapping items matched with SimpleReplaceHandler ...
This infinite loop occured only when the replacement object is just a wrapping of the matching object ; after replacement, the new object was inspected for matching objects.
Example: infinite loop if we want to wrap all foo(...) functions with the function ROUND in the following query:
SELECT foo(foo(123)) FROM myTable
Expected result:
SELECT ROUND(foo(ROUND(foo(123)))) FROM myTable
But generated result was:
SELECT ROUND(ROUND(ROUND(......foo(foo(123))))) FROM myTable
Incomplete handling of delimited aliases ...
Between double quotes an alias could contain any character, but it seems that the dot (.) was interpreted anyway (as table/column separator) before this fix.
Finishing a query with a comment triggered an error ...
The function
CENTROIDreturns a geometry not a numeric ...In addition to this bug correction, a translation of
CENTROIDusing PgSphere has been implemented.See on GitHub: 6106390... and 3306dec...
Strange tree generation for
NATURAL JOINs ...The "normal"
JOIN(e.g.A JOIN B ON A.id = B.id JOIN C ON B.id = C.id) is correctly interpreted (e.g.( (A JOIN B ON A.id = B.id) JOIN C ON B.id = C.id )). But with aNATURAL JOIN, an ADQL instruction likeA NATURAL JOIN B NATURAL JOIN Cgives( A NATURAL JOIN (B NATURAL JOIN C) )instead of( (A NATURAL JOIN B) NATURAL JOIN C ).For PSQL translator, cast numeric parameters of mathematical functions ...
DOUBLE and REAL parameters of mathematical functions must be casted into NUMERIC. Otherwise Postgres rejects the query.
Escape single and double quotes as expected ...
A string constant in ADQL is enclosed between single quotes. But is is also possible to have single quotes being part of the string constant, by doubling these single quotes, as show below:
SELECT 'foo''s bar' FROM myTable
The result of a such query should return the string
foo's bar. But the library did not do that until this commit.The same bug but about double quotes is also fixed.
Fix the possibility to enable the DEBUG mode in the parser. ...
Since the version 1.3, the DEBUG mode was disabled by default, but it was surprisingly impossible to enable it again. Now, the DEBUG mode is still disabled by default as promessed in version 1.3, but it can be enabled using the function setDebug(boolean).
No metadata set for a sub-query ...
Due to this omission, it was impossible to make any reference to any column returned by this sub-query in the parent query. (see the JUnit test for a concrete example)
The keyword
ASfor SELECT item aliases is optional ...Before this correction the alias was optional but not the keyword
AS. Now, if the alias is provided, it may be specified with OR withoutAS.Recursive replacement with SimpleReplaceHandler ...
For instance: if all mathematical functions must be replaced by a dumb UDF named 'foo' in the ADQL query:
SELECT sqrt(abs(81)) FROM myTable
the result should be:
SELECT foo(foo(81)) FROM myTable
but before this correction it was:
SELECT foo(abs(81)) FROM myTable
NullPointerException for math functions ...
Some functions like
PI()andRAND()were affected by this bug.Incorrect or incomplete translation from ADQL to SQL ...
- The character ' was not escaped. Now, all occurences of ' are replaced by '' in the SQL translation.
- In PostgreSQL: numerical parameters of mathematical functions (e.g.
LOG(),LOG10()) were not casted into NUMERIC. Without this CAST, PostgreSQL rejects quite often the query.
- The character ' was not escaped. Now, all occurences of ' are replaced by '' in the SQL translation.
ORDER BYandGROUP BY...a. In
ORDER BY,GROUP BYandUSINGonly regular and delimited identifiers are accepted, not qualified column names.For instance:
SELECT table.column_name FROM table ORDER BY table.column_name
is wrong. We should instead write:
SELECT table.column_name FROM table ORDER BY column_name
or
SELECT table.column_name AS mycol FROM table ORDER BY mycol
b. No SELECT item index in GROUP BY
According to the ADQL grammar, a GROUP BY item must be a column name or an alias. Before this correction, the index of a SELECT item could have been provided as it is possible for ORDER BY. This is no longer possible. The ADQL parser will accept only column name or alias in a GROUP BY clause.
c. But a qualified identifier in GROUP BY is allowed
For instance, the following ADQL query is correct:
SELECT * FROM table GROUP BY table.oid
See on GitHub: 7a70c60... and 8e2fa9f...
Fake schema name ...
Before this correction, it was possible to write the following ADQL query:
SELECT * FROM fakeSchema.myTable
...although the table
myTablewas defined in the tables metadata (e.g. TAP_SCHEMA) with no schema. Now, it is no longer possible: if a table is defined no schema asmyTableit MUST NOT be prefixed by any schema name. But as before, if a table is defined in the tables metadata (e.g. TAP_SCHEMA) with a schema, this latter MAY prefix the table name in an ADQL query.Functions inside functions ...
Functions whose some parameters are another function were not correctly identified: since the inner functions were not yet identified, their type was UNKNOWN and so it makes the identification of the parent function much easier since an UNKNOWN parameter is not checked. But, it was a problem if the parameter occurs to be finally of the wrong type.
Declaration of UDF parameters ...
Unknown datatypes in the declaration of User Defined Functions were reported with a confusing error message. Now, the error message specifies such datatype as
param<i>(<i> being the index of the parameter).Besides types having space like
double precisionwere not supported: they throw an "unknown datatype" error. Now, more database datatypes and in particulardouble precisionandcharacter varyingare supported."aSchema"."aTable.WithADot"...This qualified table name was interpreted similarly as the table
"aSchema"."WithADot", or in other words, the tableWithADotinside the schemaaSchema. Now, it will really be interpreted as a table namedaTable.WithADotinside the schemaaSchema.
v1.3 - 07th May 2015
This sub-version fixes also few (but quite important) bugs and adds a better support for STC-S expressions and UDFs.
STC-S expressions are now checked! ...
STC-S expressions like a region definition or a coordinate system, as restricted by the TAP protocol (see 6. Use of STC-S in TAP (informative)) are now checked by the library. A syntax mistake will be notified with a ParserException.
Limits on geometries, coordinate systems and UDFs ...
DBChecker has been modified in order to be also able to check whether the used geometrical functions, coordinate systems and User Defined Functions are allowed. For that, a list of allowed items may be provided in the constructor. For geometries, each item of the list must be a function name (e.g. AREA, COORDSYS, BOX, CIRCLE). For coordinate system, a kind of regular expression (e.g.
ICRS * *) is expected for each item. But for UDFs, each item must be an instance of FunctionDef in which a UserDefinedFunction may be provided in order to specify how to translate the function.Warning: The possibility to list coordinate systems directly in the parser has been removed. Now, verification of coordinate systems must be done afterwards using a QueryChecker (see A.3. Checker to see how).
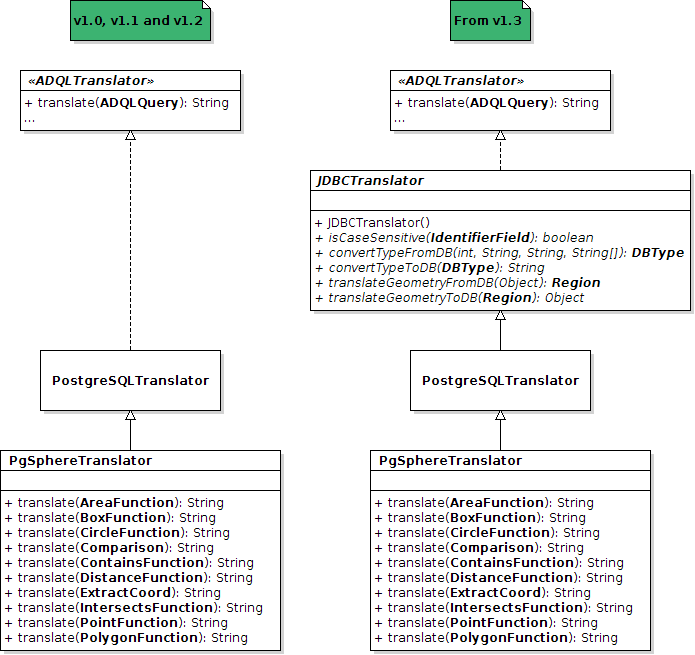
New translator: JDBCTranslator ...
Actually, it is not really about a new translator. JDBCTranslator is an abstract class between the interface ADQLTranslator and the concrete translator PostgreSQLTranslator. The idea is to use this abstract class for any other translator into SQL language. Indeed, the translation into SQL is very similar in all DBMS. So in this abstract translator all common instructions in ADQL and SQL are already translated ; only functions related to geometrical functions and column types are left for implementation. Thus, a huge work can be avoided while willing to support a new SQL-based translator.
This modification has no impact at all if you are already using PostgreSQLTranslator and/or PgSphereTranslator.
Fix bad translation of
NOT BETWEEN...Before this fix,
NOT BETWEENwere translated by PostgreSQLTranslator intoBETWEEN. So, the negation was forgotten. This grave mistake is now fixed!Fix bad translation of
SELECT table.*...table.*was translated as provided...which is a grave mistake in case the TAP table content is different from the database table. This should be translated by replacing this "joker" by the full list of columns as described in the TAP metadata. It is actually the behavior of the general "joker"*.Support of escaped characters into string constants for the PostgreSQL translation ...
A string like
'foo\'bar\''contains twice the same escaped character:'. However, this escaped string is not interpreted as one by Postgres by default. To specify a string may contain escaped characters, it must be prefixed byE(in upper- or lower-case). The library was not doing so before this version 1.3 which is now prefixing string constants only when at least one \ is detected:E'foo\'bar\''.Fix bad automatic aliases ...
When no alias is specified for a SELECT item, the library is adding one automatically. Thus, the alias of a column is the name of the column and the alias of a function is the function name. For a concatenation or mathematical operations, the sign of the operation is used as alias. However, before this new sub-version, double quotes were not surrounding those aliases. That is a problem for mathematical operations which were then interpreted as a real operation rather than just an alias: a SQL error were then returned by the DBMS.
This bug is now fixed: automatic aliases are always surrounded by double quotes.
Parser debugging disabled by default ...
The DEBUG mode of the parser was enabled by default...meaning that all grammar rules were listed when parsing a query. This mode is still possible but now disabled by default.
v1.2 - 15th April 2014
This sub-version is just a correction of several bugs often encountered. Here are the major bugs fixed (the list is not exhaustive):
Missing some column positions ...
Parse exceptions about columns inside the clauses ORDER and GROUP BY had no information about the position in the query. This is now fixed!
Brackets had no effect! ...
Brackets in mathematical or logical operations had no effect when translating the query in SQL. The notion of priority was well read and represented in the object tree, but it was not used during the SQL translation.
For instance, the following ADQL query:
SELECT oid AS oid FROM A WHERE oid = 1 AND (colTxtB = 'toto' or colC*(colA-colB) > colD);
...was translated in SQL:
SELECT oid AS oid FROM A WHERE oid = 1 AND colTxtB = 'toto' OR colC*colA-colB > colD
Functions ROUND and TRUNCATE may have 2 parameters ...
In conformity with the IVOA definition, these two functions must have either 1 or 2 parameters. Before, the library was allowing just one parameter. Now, both are allowed.
Subqueries and parent's columns ...
The query checker was not allowing subqueries to use columns of the parent/main query.
SELECT oid, colA, colB FROM A WHERE ... AND (SELECT COUNT(*) FROM B WHERE B.oid = A.oid) > 1;
Problem with too many NATURAL JOINS and JOINs USING ...
After 3-4 NATURAL joins or joins using the keyword USING, the query checker was lost and returned wrong errors. Columns which were supposed to be joined were not seen like that by the checker. Now they are!
For example: let's suppose that we have 3 tables (A, B and C) and all of them have a column with the same name: oid. The following query:
SELECT oid FROM A NATURAL JOIN B NATURAL JOIN C; -- which more or less equivalent to: SELECT oid FROM A JOIN B USING(oid) JOIN C USING(oid);
With the version 1.1, we get the following error:
((X)) 1 unresolved identifiers ! * [l.1 c.8 - l.1 c.11] - Ambiguous column name "oid" ! It may be (at least) "A.oid" or "B.oid".
DefaultUDF(String,ADQLOperand[]) threw an exception! ...
When creating your own user defined function with some parameters using DefaultUDF, you may have had an ArrayIndexOutOfBoundsException. This bug is now fixed!
v1.1 - 15th June 2012
Problem of sub-query alias fixed! ...
Before this correction, the alias of a sub-query in the clause FROM was not taken into account when checking the query with DBChecker.
For instance, the following query:
SELECT q.flux, q.filter, p.oid, p.ra, p.dec FROM (SELECT flux, filter, oidref FROM flux WHERE flux BETWEEN 0 AND 10) AS q INNER JOIN basic ON q.oidref = p.oid;
In this case, the following error was returned:
((X)) 7 unresolved identifiers ! * [l.1 c.8 - l.1 c.14] - Unknown column "q.flux" ! * [l.1 c.16 - l.1 c.24] - Unknown column "q.filter" ! * [l.1 c.26 - l.1 c.31] - Unknown column "p.oid" ! * [l.1 c.33 - l.1 c.37] - Unknown column "p.ra" ! * [l.1 c.39 - l.1 c.44] - Unknown column "p.dec" ! * [l.2 c.99 - l.2 c.107] - Unknown column "q.oidref" ! * [l.2 c.110 - l.2 c.115] - Unknown column "p.oid" ! adql.db.exception.UnresolvedIdentifiersException: 7 unresolved identifiers ! at adql.db.DBChecker.check(DBChecker.java:170) at adql.parser.ADQLParser.QueryExpression(ADQLParser.java:539) at adql.parser.ADQLParser.Query(ADQLParser.java:473) at adql.parser.ADQLParser.parseQuery(ADQLParser.java:269) at adql.demo.ADQLDemo.main(ADQLDemo.java:125)
The problem has been fixed by setting a default description of the sub-query into the ADQLTable which describes it.
See the following correction for more details.Method ADQLTable.refreshDBLink() added! ...
This method builds a DefaultDBTable object describing the table returned by the represented sub-query.
- Note 1: This method has no effect if the ADQLTable does not represent a sub-query or has no alias.
- Note 2: This method is called automatically by the function getDBColumns() if no DB link has been set.